This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
This dataset aims to accelerate the development of event-based algorithms and methods for edge cases encountered by autonomous systems in dynamic environments. 94-171) Demonstration Noisy Measurement File from United States Census Bureau What are people doing with open data?
MongoDB’s robust time series data management allows for the storage and retrieval of large volumes of time-series data in real-time, while advanced machine learning algorithms and predictive capabilities provide accurate and dynamic forecasting models with SageMaker Canvas. Setup the Database access and Network access.
Data Science is a field that extracts useful information from loads of structured and unstructured data using algorithms, statistics, and programming. The concept of data science was first introduced in 2001, but it started gaining popularity in 2010. It may be dealing with data, but it doesn’t have a lot to do with databases.
github.com Their core repos consist of SparseML: a toolkit that includes APIs, CLIs, scripts and libraries that apply optimization algorithms such as pruning and quantization to any neural network. Neural Magic Neural Magic has 6 repositories available. Follow their code on GitHub. SparseZoo: a model repo for sparse models. Connected Papers
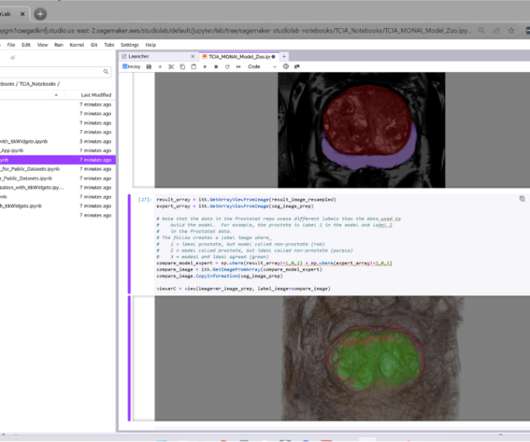
His team founded The Cancer Imaging Archive (TCIA) in 2010, which the research community has leveraged to publish over 200 datasets related to manuscripts, grants, challenge competitions, and major NCI research initiatives. These datasets have been discussed in over 1,500 peer reviewed publications.
Summary: Apache Cassandra and MongoDB are leading NoSQL databases with unique strengths. Introduction In the realm of database management systems, two prominent players have emerged in the NoSQL landscape: Apache Cassandra and MongoDB. MongoDB is another leading NoSQL database that operates on a document-oriented model.
Overview of RAG RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and natural language processing (NLP) tasks since 2010. Load into the SQL database for later querying. Modern LLMs are good at generating SQL.
github.com Their core repos consist of SparseML: a toolkit that includes APIs, CLIs, scripts and libraries that apply optimization algorithms such as pruning and quantization to any neural network. Neural Magic Neural Magic has 6 repositories available. Follow their code on GitHub. SparseZoo: a model repo for sparse models. Connected Papers
This is accomplished by breaking the problem into independent parts so that each processing element can complete its part of the workload algorithm simultaneously. From 2010 onwards, other PBAs have started becoming available to consumers, such as AWS Trainium , Google’s TPU , and Graphcore’s IPU.
Advance algorithms and analytic approaches for early prediction of AD/ADRD, with an emphasis on explainability of predictions. Top solvers from Phase 2 demonstrate algorithmic approaches on diverse datasets and share their results at an innovation event. Phase 2 [Build IT!] Phase 3 [Put IT All Together!]
And so were in a position to compare the results of human effort (aided, in many cases, by systematic search) with what we can automatically do by the algorithmic process of adaptive evolution. Butas was actually already realized in the mid-1990sits still possible to use algorithmic methods to fill in pieces of patterns.
Algorithms are important and require expert knowledge to develop and refine, but they would be useless without data. These datasets, essentially large collections of related information, act as the training field for machine learning algorithms. This involves feeding the images and their corresponding labels into an algorithm (e.g.,
Large language models (LLMs) can help uncover insights from structured data such as a relational database management system (RDBMS) by generating complex SQL queries from natural language questions, making data analysis accessible to users of all skill levels and empowering organizations to make data-driven decisions faster than ever before.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content