This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
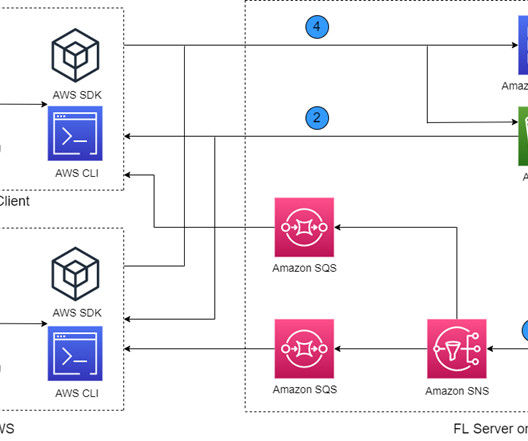
Machine learning (ML), especially deep learning, requires a large amount of data for improving model performance. It is challenging to centralize such data for ML due to privacy requirements, high cost of data transfer, or operational complexity. The ML framework used at FL clients is TensorFlow.
This dataset aims to accelerate the development of event-based algorithms and methods for edge cases encountered by autonomous systems in dynamic environments. 94-171) Demonstration Noisy Measurement File from United States Census Bureau What are people doing with open data?
Stage 2: Machine learning models Hadoop could kind of do ML, thanks to third-party tools. But in its early form of a Hadoop-based ML library, Mahout still required data scientists to write in Java. And it (wisely) stuck to implementations of industry-standard algorithms. Those algorithms packaged with scikit-learn?
It’s also an area that stands to benefit most from automated or semi-automated machine learning (ML) and natural language processing (NLP) techniques. Over the past several years, researchers have increasingly attempted to improve the data extraction process through various ML techniques. This study by Bui et al.
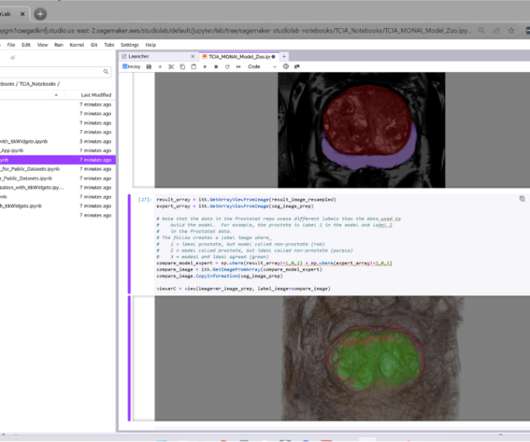
Amazon SageMaker Studio Lab provides no-cost access to a machine learning (ML) development environment to everyone with an email address. Therefore, you can scale your ML experiments beyond the free compute limitations of Studio Lab and use more powerful compute instances with much bigger datasets on your AWS accounts.
I am referring to Vertex, the new machine learning platform that can help you train and deploy ML models and AI applications, and customize large language models (LLMs) for use in your AI-powered applications which is a new product set to be a game changer in the AI tech race. What is Google Earth Engine? What is Vertex?
Participants demonstrated outstanding ability in utilizing ML and AI to examine and predict startup success within the venture capital landscape and refine investment strategies. Annual Increase in Funding Amounts Since 2010, the average amount raised per startup funding round has increased by 15% annually.
MongoDB’s robust time series data management allows for the storage and retrieval of large volumes of time-series data in real-time, while advanced machine learning algorithms and predictive capabilities provide accurate and dynamic forecasting models with SageMaker Canvas. Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB.
In our pipeline, we used Amazon Bedrock to develop a sentence shortening algorithm for automatic time scaling. Here’s the shortened sentence using the sentence shortening algorithm. She specializes in leveraging AI and ML to drive innovation and develop solutions on AWS. Partner Solutions Architect at AWS, specializing in AI/ML.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
The Continuing Story of Neural Magic Around New Year’s time, I pondered about the upcoming sparsity adoption and its consequences on inference w/r/t ML models. But first… a word from our sponsors: [link] If you enjoy the read, help us out by giving it a ?? and share with friends! The company is Neural Magic. Follow their code on GitHub.
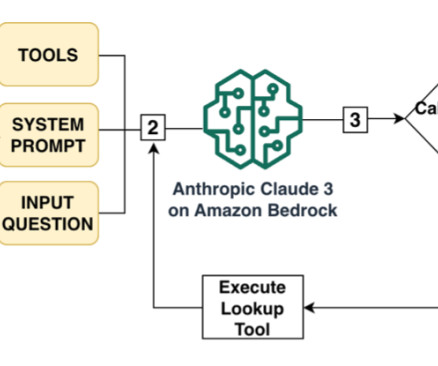
At its core, Amazon Bedrock provides the foundational infrastructure for robust performance, security, and scalability for deploying machine learning (ML) models. The serverless infrastructure of Amazon Bedrock manages the execution of ML models, resulting in a scalable and reliable application.
Did you know that big data consumption increased 5,000% between 2010 and 2020 ? It is a promising position for those skilled in mechanics, electronics, data analytics and ML. recognize objects; give meaningful answers to questions; reach decisions that traditional computer algorithms cannot make. This should come as no surprise.
Why is it that Amazon, which has positioned itself as “the most customer-centric company on the planet,” now lards its search results with advertisements, placing them ahead of the customer-centric results chosen by the company’s organic search algorithms, which prioritize a combination of low price, high customer ratings, and other similar factors?
The contributors recommend using algorithms like Apriori Algorithm to analyze the Market Basket Analysis. While this data is not fresh, it is from 2010-2012, we added it to the list because of the holiday sales data that can be used and could still be relevant. To learn more about ML and retailers, click here.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning.
Overview of RAG RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and natural language processing (NLP) tasks since 2010. The search precision can also be improved with metadata filtering.
The Continuing Story of Neural Magic Around New Year’s time, I pondered about the upcoming sparsity adoption and its consequences on inference w/r/t ML models. But first… a word from our sponsors: If you enjoy the read, help us out by giving it a ?? and share with friends! The company is Neural Magic. Follow their code on GitHub.
In the intricate world of machine learning algorithms, probability serves as the foundational pillar. To truly decipher the mechanisms and theories of these algorithms, it’s essential to have a firm understanding of probability fundamentals. Generates a bar chart depicting the count of rainy days in June from 2010 to 2022. .
Control algorithm. It provides an out-of-the-box implementation of Madgwick’s filter , an algorithm that fuses angular velocities (from the gyroscope) and linear accelerations (from the accelerometer) to compute an orientation wrt the Earth’s magnetic field. Depending on the context, this assumption may be too optimistic.
After the release of the iPad in 2010 Craig Hockenberry discussed the great value of communal computing but also the concerns : “When you pass it around, you’re giving everyone who touches it the opportunity to mess with your private life, whether intentionally or not. This expectation isn’t a new one either.
Finally, one can use a sentence similarity evaluation metric to evaluate the algorithm. One such evaluation metric is the Bilingual Evaluation Understudy algorithm, or BLEU score. The idea of sampling an attention trajectory as an estimation was taken from a Reinforcement Learning algorithm called REINFORCE[88]. Paragios N.
Advance algorithms and analytic approaches for early prediction of AD/ADRD, with an emphasis on explainability of predictions. Top solvers from Phase 2 demonstrate algorithmic approaches on diverse datasets and share their results at an innovation event. Paola Ruíz Puente is a Biomedical Engineer amd the AI/ML manager at IGC Pharma.
E11 Bio, a Bay area-based non-profit staffed by neuroanatomists and bioengineers, is creating a platform not only to better visualize the neural connections but also to improve the algorithms available to map these circuits. Modern researchers rely on algorithms for help.
About the Authors Mithil Shah is a Principal AI/ML Solution Architect at Amazon Web Services. He helps commercial and public sector customers use AI/ML to achieve their business outcome. Santosh Kulkarni is an Senior Solutions Architect at Amazon Web Services specializing in AI/ML.
Understanding the DE-SynPUF dataset The DE-SynPUF dataset is a synthetic database released by the Centers for Medicare and Medicaid Services (CMS), designed to simulate Medicare claims data from 2008–2010. Due to file size limitations, each data type in the CMS Linkable 2008–2010 Medicare DE-SynPUF database is released in 20 separate samples.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content