This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Identifying important features using Python Introduction Features are the foundation on which every machine-learning model is built. What we are looking for in these algorithms is to output a list of features along with corresponding importance values. We will cover very rudimentary methods, along with quite sophisticated algorithms.
In Otter-Knoweldge, we use different pre-trained models and/or algorithms to handle the different modalities of the KG, what we call handlers. These handlers might be complex pre-trained deep learning models, like MolFormer or ESM, or simple algorithms like the morgan fingerprint. Nucleic Acids Research, 40(D1):D1100–D1107, 09 2011.
Today, almost all high-performance parsers are using a variant of the algorithm described below (including spaCy). It’s now possible for a tiny Python implementation to perform better than the widely-used Stanford PCFG parser. 2,020 Python ~500 Redshift 93.6% Parser Accuracy Speed (w/s) Language LOC Stanford PCFG 89.6%
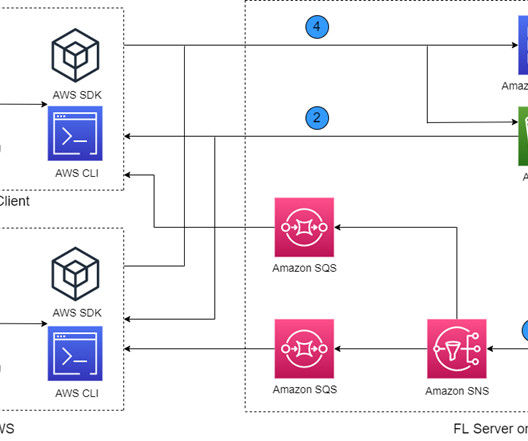
Challenges in FL You can address the following challenges using algorithms running at FL servers and clients in a common FL architecture: Data heterogeneity – FL clients’ local data can vary (i.e., Despite these challenges of FL algorithms, it is critical to build a secure architecture that provides end-to-end FL operations.
Note : This blog is more biased towards python as it is the language most developers use to get started in computer vision. Python / C++ The programming language to compose our solution and make it work. Why Python? Easy to Use: Python is easy to read and write, which makes it suitable for beginners and experts alike.
TensorFlow implements a wide range of deep learning and machine learning algorithms and is well-known for its adaptability and extensive ecosystem. In finance, it's applied for fraud detection and algorithmic trading. Integration: Strong integration with Python, supporting popular libraries such as NumPy and SciPy.
The short story is, there are no new killer algorithms. The way that the tokenizer works is novel and a bit neat, and the parser has a new feature set, but otherwise the key algorithms are well known in the recent literature. Some might also wonder how I get Python code to run so fast.
Founded in 2011, Talent.com is one of the world’s largest sources of employment. The performance of Talent.com’s matching algorithm is paramount to the success of the business and a key contributor to their users’ experience. The client registers smddp as a backend for PyTorch.
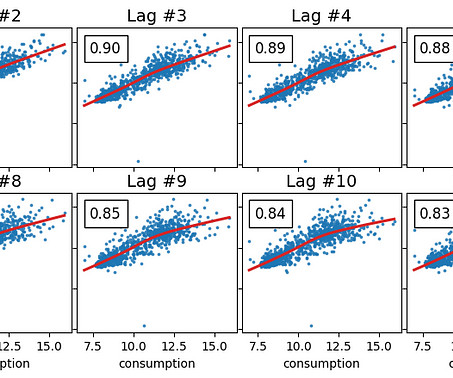
We can plot these with the help of the `plot_pacf` function of the statsmodels Python package: [link] Partial autocorrelation plot for 12 lag features We can clearly see that the first 9 lags possibly contain valuable information since they’re out of the bluish area.
spaCy is an open-source library for industrial-strength natural language processing in Python. In 2011, deep learning methods were proving successful for NLP, and techniques for pretraining word representations were already in use. This is exactly what algorithms like word2vec, GloVe and FastText set out to solve.
Most publicly available fraud detection datasets don’t provide this information, so we use the Python Faker library to generate a set of transactions covering a 5-month period. We use Amazon SageMaker to train a model using the built-in XGBoost algorithm on aggregated features created from historical transactions.
Ensemble learning refers to the use of multiple learning models and algorithms to gain more accurate predictions than any single, individual learning algorithm. This way, you don’t need to manage your own Docker image repository and it provides more flexibility to running training scripts that need additional Python packages.
We then also cover how to fine-tune the model using SageMaker Python SDK. FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2 models using the SageMaker Python SDK. You can access the Meta Llama 3.2
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content