This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Introduction Google’s BigQuery is an enterprise-grade cloud-native data warehouse. BigQuery was first launched as a service in 2010, with general availability in November 2011.
Since 2011, national math test scores from the National Assessment of Educational Progress, or NAEP, fell by 17 points for eighth graders and 10 points for fourth graders in data analysis, statistics and probability. Despite these efforts, programs in datascience at the K-12 level remain few and far between.
Shoppers probably dont realize how large a role datascience plays in retail. Those are just some of the insights that data scientist Vivek Anand extracts to inform decision makers at the Gap , a clothing company headquartered in San Francisco. But underneath they are similar.
Introduction Apache Kafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011. It is a famous Scala-coded data processing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time.
Bitcoin is currently trading at over $1250 and if you are someone who invested a grand in bitcoins back in 2011, your investments are potentially worth over $600K. The post Blockchains could be every Data Scientist’s dream appeared first on Dataconomy.
Big Data tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. Big Data wurde zum Business-Sprech der darauffolgenden Jahre. In der Parallelwelt der ITler wurde das Tool und Ökosystem Apache Hadoop quasi mit Big Data beinahe synonym gesetzt. ” Towards DataScience.
There are three main reasons why datascience has been rated as a top job according to research. Firstly, the number of available job openings is rapidly increasing and the highest in comparison to other jobs, datascience has an extremely high job satisfaction rating, and the median annual salary base is undeniably desirable.
The AI used by the DeepMind team was trained on data from the Materials Project. That’s an international research group founded at the Lawrence Berkeley National Laboratory in 2011. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
DataScience Movies has been sprawling in the sector since years now, and people have started to understand its significance today. Numerous movies have been produced and made that enables you to understand the ways in which Artificial Intelligence, Machine Learning, Data and Information have played crucial roles.
As newer fields emerge within datascience and the research is still hard to grasp, sometimes it’s best to talk to the experts and pioneers of the field. He gave the Inaugural IMS Grace Wahba Lecture in 2022, the IMS Neyman Lecture in 2011, and an IMS Medallion Lecture in 2004. Recently, we spoke with Michael I.
Even if all the code runs and the model seems to be spitting out reasonable answers, it’s possible for a model to encode fundamental datascience mistakes that invalidate its results. As a data scientist, one of my passions is to reproduce research papers as a learning exercise. See the source for this graphic.).
Edited Photo by Taylor Vick on Unsplash In ML engineering, data quality isn’t just critical — it’s foundational. Since 2011, Peter Norvig’s words underscore the power of a data-centric approach in machine learning. This member-only story is on us. Upgrade to access all of Medium.
I’m excited to be part of CDS because it provides a unique environment where cutting-edge datascience methods can be developed and applied to push the boundaries of science,” said Ho. “I I look forward to collaborating with fellow researchers and students to explore new frontiers in foundation models for science.”
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for datascience, machine learning (ML), and computational science. Given the importance of Jupyter to data scientists and ML developers, AWS is an active sponsor and contributor to Project Jupyter.
In the realm of Big Data, there are two prominent architectural concepts that perplex companies embarking on the construction or restructuring of their Big Data platform: Lambda architecture or Kappa architecture. Its focus on unique, ongoing events allows for effective and responsive data processing.
There are plenty of datascience or data analytics degrees available for those looking for a traditional education approach to learning a new skill. This year we’re welcoming some great data analytics degrees education partners to ODSC East.
Since 2011, a man by the name of Gert-Jan Oskam had been paralyzed from the hips down after a motorcycle accident. You can also get datascience training on-demand wherever you are with our Ai+ Training platform. Due to the accident, his spine had become injured and communication between it and his brain had been broken.
Nucleic Acids Research, 40(D1):D1100–D1107, 09 2011. Sci Data 10, 67 (2023). Otter-Knowledge was originally published in IBM DataScience in Practice on Medium, where people are continuing the conversation by highlighting and responding to this story. Overington. ISSN 0305–1048. doi: 10.1093/nar/gkr777. Huang, K. &
Thirdly, we use Grubbs test to test whether outliers are present in data. Chi-squared, Dixon and Grubbs tests are available in outliers R package (Komsta, 2011). How to Test for Identifying Outliers in R Using RStudio Subscribe to YouTube Channel Don’t forget to check: How to Clean Data in R References Komsta, L. Millard, S.P.
Analyst Michelle Goetz, a well known advisor to enterprise architects, chief data officers, and business analysts, has been tracking this market for some time. She’s seen the evolution of the self-service analytics market from decision systems to business intelligence to data visualization to datascience and automated intelligence.
Science and technology have evolved rapidly since then, providing far more granular data, reflecting what is happening at a much more localized level. Today, datascience enables you to understand the real-world impact of weather events as they happen.
Science and technology have evolved rapidly since then, providing far more granular data, reflecting what is happening at a much more localized level. Today, datascience enables you to understand the real-world impact of weather events as they happen.
Then in 2022 a nice book on the Game of Life came out (by Nathaniel Johnston and Dave Greene, the latter of whom had actually been at our Summer School back in 2011 ). But the project of studying the metaengineering of the Game of Life stayed on my to do list (and a couple of students at our Wolfram Summer School worked on it).
The resulting training dataset from the processing job can be saved directly as a CSV for model training, or it can be bulk ingested into an offline feature group that can be used for other models and by other datascience teams to address a wide variety of other use cases.
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). They’re mostly trained on general domain corpora, making them less effective on domain-specific tasks.
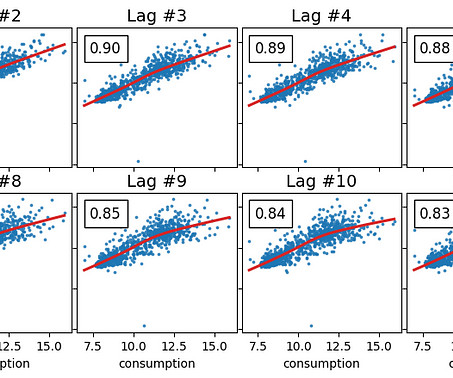
As described in the previous article , we want to forecast the energy consumption from August of 2013 to March of 2014 by training on data from November of 2011 to July of 2013. Experiments Before moving on to the experiments, let’s quickly remember what’s our task.
For the purposes of this tutorial, I’ve chosen the London Energy Dataset which contains the energy consumption of 5,567 randomly selected households in the city of London, UK for the time period of November 2011 to February 2014.
Editor's Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners. Here are some resources for more information: Hasibuan, Z. Ahmad, M., & Selviandro, N. Ekanayake, B.,
In 2011, H2O.ai Companies like PayPal , Wells Fargo , and MarketAxess leverage H2O.ai's machine learning capabilities to drive datascience initiatives. is suitable for enterprises and data scientists looking to accelerate their machine-learning workflows with automated tools and scalable solutions.
jpg': {'class': 111, 'label': 'Ford Ranger SuperCab 2011'}, '00236.jpg': jpg': {'class': 102, 'label': 'Ferrari California Convertible 2012'}, Since this isn’t an article on data cleaning/preparation, for this initial step, I’m just going to show my code with comments.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content