This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for datascience, machine learning (ML), and computational science. Given the importance of Jupyter to data scientists and ML developers, AWS is an active sponsor and contributor to Project Jupyter.
Edited Photo by Taylor Vick on Unsplash In ML engineering, data quality isn’t just critical — it’s foundational. Since 2011, Peter Norvig’s words underscore the power of a data-centric approach in machine learning. Yet, this perspective often gets sidelined and there was never a consensus in the ML community about it.
Businesses are increasingly using machine learning (ML) to make near-real-time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products and services. As a result, some enterprises have spent millions of dollars inventing their own proprietary infrastructure for feature management.
As newer fields emerge within datascience and the research is still hard to grasp, sometimes it’s best to talk to the experts and pioneers of the field. He gave the Inaugural IMS Grace Wahba Lecture in 2022, the IMS Neyman Lecture in 2011, and an IMS Medallion Lecture in 2004. Recently, we spoke with Michael I.
Text generation using RAG with LLMs enables you to generate domain-specific text outputs by supplying specific external data as part of the context fed to LLMs. JumpStart is a machine learning (ML) hub that can help you accelerate your ML journey. SageMaker Savings Plans apply only to SageMaker ML Instance usage.
Analyst Michelle Goetz, a well known advisor to enterprise architects, chief data officers, and business analysts, has been tracking this market for some time. She’s seen the evolution of the self-service analytics market from decision systems to business intelligence to data visualization to datascience and automated intelligence.
This guarantees businesses can fully utilize deep learning in their AI and ML initiatives. You can make more informed judgments about your AI and ML initiatives if you know these platforms' features, applications, and use cases. In 2011, H2O.ai Notable Use Cases in the Industry H2O.ai Guidance for Use H2O.ai Documentation H2O.ai
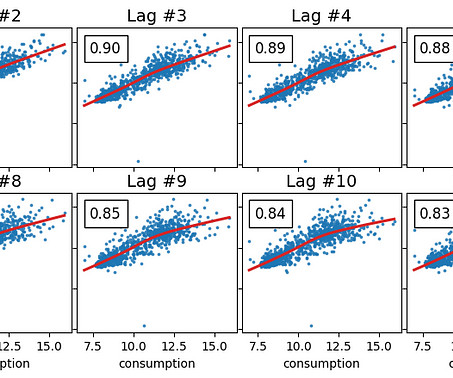
As described in the previous article , we want to forecast the energy consumption from August of 2013 to March of 2014 by training on data from November of 2011 to July of 2013. Experiments Before moving on to the experiments, let’s quickly remember what’s our task.
For the purposes of this tutorial, I’ve chosen the London Energy Dataset which contains the energy consumption of 5,567 randomly selected households in the city of London, UK for the time period of November 2011 to February 2014.
Editor's Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners. Here are some resources for more information: Hasibuan, Z. Ahmad, M., & Selviandro, N. Ekanayake, B.,
jpg': {'class': 111, 'label': 'Ford Ranger SuperCab 2011'}, '00236.jpg': jpg': {'class': 102, 'label': 'Ferrari California Convertible 2012'}, Since this isn’t an article on data cleaning/preparation, for this initial step, I’m just going to show my code with comments.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content