This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Source: Author Introduction Deeplearning, a branch of machinelearning inspired by biological neural networks, has become a key technique in artificial intelligence (AI) applications. Deeplearning methods use multi-layer artificial neural networks to extract intricate patterns from large data sets.
Machinelearning is a glass cannon. The promise and power of AI lead many researchers to gloss over the ways in which things can go wrong when building and operationalizing machinelearning models. As a data scientist, one of my passions is to reproduce research papers as a learning exercise.
This post is co-authored by Anatoly Khomenko, MachineLearning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. Founded in 2011, Talent.com is one of the world’s largest sources of employment. It’s designed to significantly speed up deeplearning model training.
To address customer needs for high performance and scalability in deeplearning, generative AI, and HPC workloads, we are happy to announce the general availability of Amazon Elastic Compute Cloud (Amazon EC2) P5e instances, powered by NVIDIA H200 Tensor Core GPUs. degree in Computer Science in 2011 from the University of Lille 1.
They’re driving a wave of advances in machinelearning some have dubbed transformer AI. Transformers made self-supervised learning possible, and AI jumped to warp speed,” said NVIDIA founder and CEO Jensen Huang in his keynote address this week at GTC. A Moment for MachineLearning. Transformers Replace CNNs, RNNs.
Meet CDS Senior Research Scientist Shirley Ho , a distinguished astrophysicist and machinelearning expert who brings a wealth of experience and innovative research to our community. What sets Dr. Ho apart is her pioneering work in applying deeplearning techniques to astrophysics.
This post is co-authored by Anatoly Khomenko, MachineLearning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. Established in 2011, Talent.com aggregates paid job listings from their clients and public job listings, and has created a unified, easily searchable platform.
This breakthrough enabled faster and more powerful computations, propelling AI research forward One notable public achievement during this time was IBM’s AI system, Watson, defeating two champions on the game show Jeopardy in 2011. This demonstrated the astounding potential of machines to learn and differentiate between various objects.
Early iterations of the AI applications we interact with most today were built on traditional machinelearning models. These models rely on learning algorithms that are developed and maintained by data scientists. For example, Apple made Siri a feature of its iOS in 2011. IBM watsonx.ai Explore watsonx.ai
& AWS MachineLearning Solutions Lab (MLSL) Machinelearning (ML) is being used across a wide range of industries to extract actionable insights from data to streamline processes and improve revenue generation. We trained three models using data from 2011–2018 and predicted the sales values until 2021.
But the machinelearning engines driving them have grown significantly, increasing their usefulness and popularity. IBM’s Watson became a TV celebrity in 2011 when it handily beat two human champions on the Jeopardy! The concepts behind this kind of text mining have remained fairly constant over the years.
JumpStart is a machinelearning (ML) hub that can help you accelerate your ML journey. There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19).
Machinelearning (ML), especially deeplearning, requires a large amount of data for improving model performance. Federated learning (FL) is a distributed ML approach that trains ML models on distributed datasets. Her current areas of interest include federated learning, distributed training, and generative AI.
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for data science, machinelearning (ML), and computational science. The distribution is versioned using SemVer and will be released on a regular basis moving forward.
Key milestones include the Turing Test, the Dartmouth Conference, and breakthroughs in machinelearning. Researchers began to focus on MachineLearning, a subfield of AI that emphasises the importance of data-driven approaches. This shift allowed systems to learn from experience and improve their performance over time.
Many Libraries: Python has many libraries and frameworks (We will be looking some of them below) that provide ready-made solutions for common computer vision tasks, such as image processing, face detection, object recognition, and deeplearning. It is a fork of the Python Imaging Library (PIL), which was discontinued in 2011.
Businesses are increasingly using machinelearning (ML) to make near-real-time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products and services. It’s easy to learn Flink if you have ever worked with a database or SQL-like system by remaining ANSI-SQL 2011 compliant.
Identifying important features using Python Introduction Features are the foundation on which every machine-learning model is built. Different machine-learning paradigms use different terminologies for features such as annotations, attributes, auxiliary information, etc. What is feature importance? XGBoost, LightGBM).
In this post, I’ll explain how to solve text-pair tasks with deeplearning, using both new and established tips and technologies. The SNLI dataset is over 100x larger than previous similar resources, allowing current deep-learning models to be applied to the problem.
The addition of language may eventually provide a means for machines to group, reason and articulate complex concepts in the future. Much the same way we iterate, link and update concepts through whatever modality of input our brain takes — multi-modal approaches in deeplearning are coming to the fore.
We will build a machinelearning model in Thinc, implement a new spaCy component, train it with the new configuration system and demonstrate how to use a pre-trained transformer model from the Hugging Face Transformers library to boost your performance. This requires three main steps.
And—as we’ll discuss later—these weights are normally determined by “training” the neural net using machinelearning from examples of the outputs we want.) In each case, as we’ll explain later, we’re using machinelearning to find the best choice of weights.
Artificial Intelligence (AI) Integration: AI techniques, including machinelearning and deeplearning, will be combined with computer vision to improve the protection and understanding of cultural assets. Preservation of cultural heritage and natural history through game-based learning. Ekanayake, B.,
Validating Modern MachineLearning (ML) Methods Prior to Productionization. Validating MachineLearning Models. When the FRB’s guidance was first introduced in 2011, modelers often employed traditional regression -based models for their business needs.
It’s widely used in production and research systems for extracting information from text, developing smarter user-facing features, and preprocessing text for deeplearning. In 2011, deeplearning methods were proving successful for NLP, and techniques for pretraining word representations were already in use.
Big Data tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. Von Data Science spricht auf Konferenzen heute kaum noch jemand und wurde hype-technisch komplett durch MachineLearning bzw. Big Data wurde zum Business-Sprech der darauffolgenden Jahre. ChatGPT basiert auf GPT-3.5
jpg': {'class': 111, 'label': 'Ford Ranger SuperCab 2011'}, '00236.jpg': Training with TFRecords vs Raw Input Most deeplearning tutorials, both Pytorch and Tensorflow, typically show you how to prepare your data for model training by using simple DataGenerators which read the raw data.
Deeplearning is likely to play an essential role in keeping costs in check. DeepLearning is Necessary to Create a Sustainable Medicare for All System. He should elaborate more on the benefits of big data and deeplearning. A lot of big data experts argue that deeplearning is key to controlling costs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









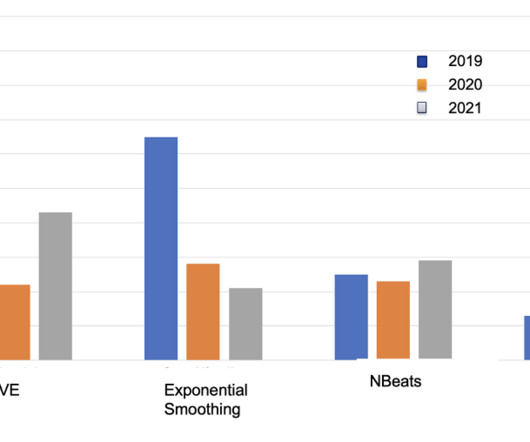


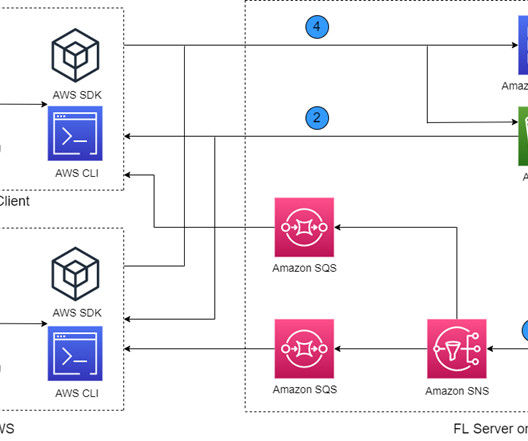






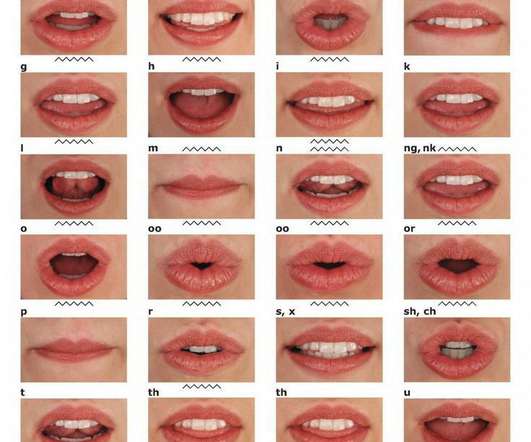
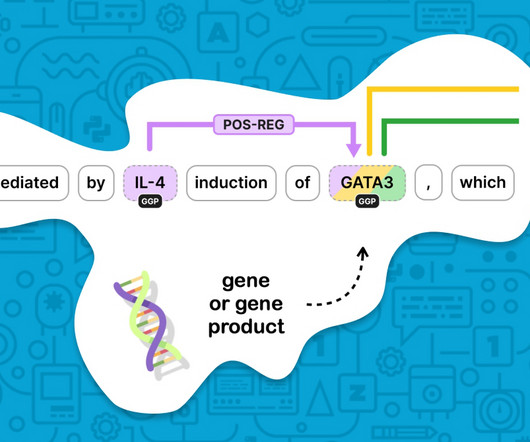
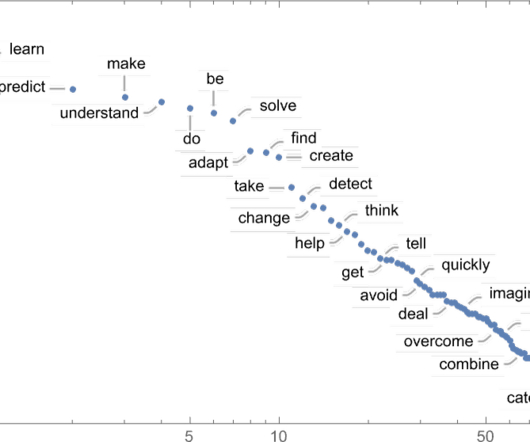












Let's personalize your content