This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
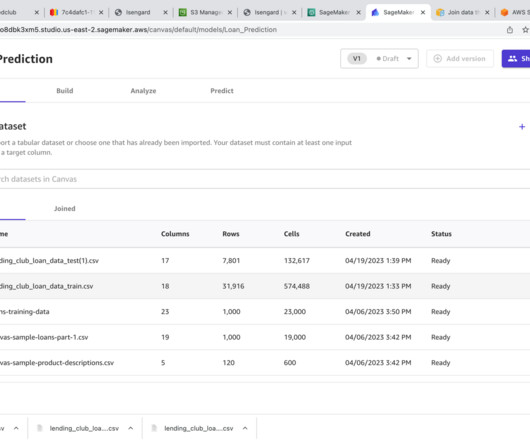
By harnessing the capabilities of generative AI, you can automate the generation of comprehensive metadata descriptions for your data assets based on their documentation, enhancing discoverability, understanding, and the overall data governance within your AWS Cloud environment. Python and boto3.
Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. Customers are building innovative generative AI applications using Amazon Bedrock APIs using their own proprietary data.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
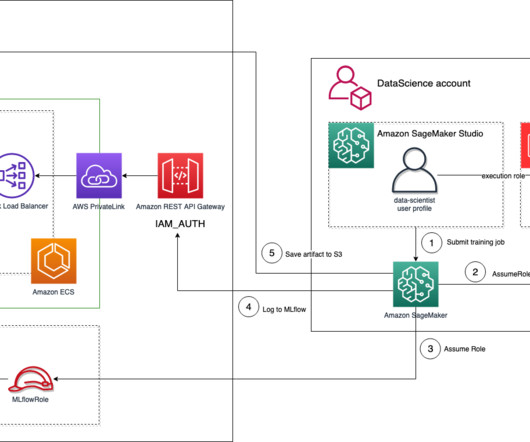
In a previous post , we discussed MLflow and how it can run on AWS and be integrated with SageMaker—in particular, when tracking training jobs as experiments and deploying a model registered in MLflow to the SageMaker managed infrastructure. To automate the infrastructure deployment, we use the AWS Cloud Development Kit (AWS CDK).
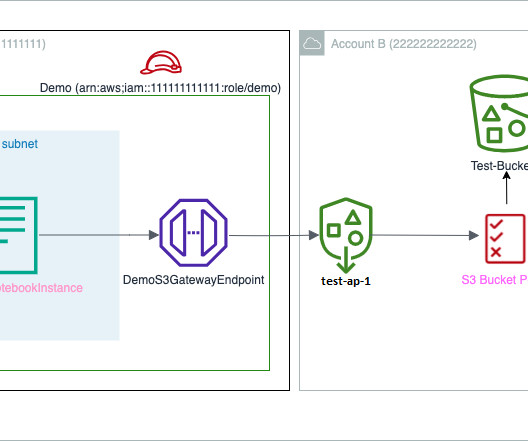
It enables secure, high-speed data copy between same-Region access points using AWS internal networks and VPCs. Configure AWS Identity and Access Management (IAM) permissions and policies in Account A. S3 Access Points simplifies the management of access permissions specific to each application accessing a shared dataset.
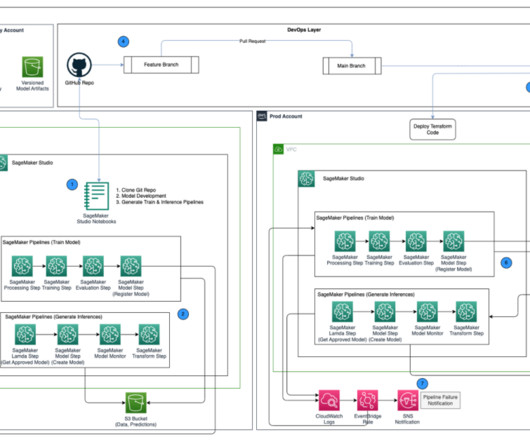
Central model registry – Amazon SageMaker Model Registry is set up in a separate AWS account to track model versions generated across the dev and prod environments. with administrative privileges installed on AWS Terraform version 1.5.5 After the key is provisioned, it should be visible on the AWS KMS console.
During AWS re:Invent 2022, AWS introduced new ML governance tools for Amazon SageMaker which simplifies access control and enhances transparency over your ML projects. Depending on your governance requirements, Data Science & Dev accounts can be merged into a single AWS account.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics. Work by Hinton et al.
With SageMaker, data scientists and developers can quickly build and train ML models, and then deploy them into a production-ready hosted environment. In this post, we demonstrate how to use the managed ML platform to provide a notebook experience environment and perform federated learning across AWS accounts, using SageMaker training jobs.
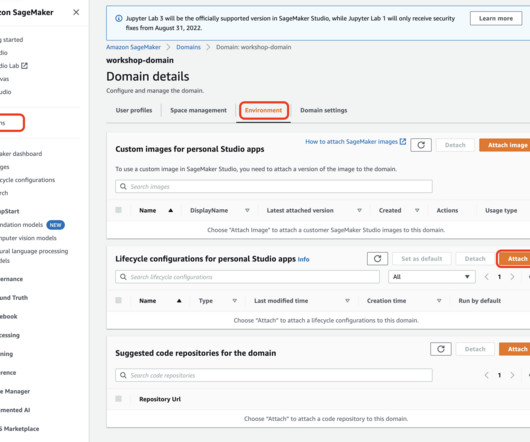
For provisioning Studio in your AWS account and Region, you first need to create an Amazon SageMaker domain—a construct that encapsulates your ML environment. The preceding event is logged in AWS CloudTrail with the name AddMemberToGroup. The EventBridge rule triggers the target AWS Lambda function.
You can manage app images via the SageMaker console, the AWS SDK for Python (Boto3), and the AWS Command Line Interface (AWS CLI). The Studio Image Build CLI lets you build SageMaker-compatible Docker images directly from your Studio environments by using AWS CodeBuild. Environments without internet access.
Prerequisites The following prerequisites are needed to implement this solution: An AWS account with permissions to create AWS Identity and Access Management (IAM) policies and roles. About the Authors Ajjay Govindaram is a Senior Solutions Architect at AWS. Varun Mehta is a Solutions Architect at AWS.
During AWS re:Invent 2022, AWS introduced new ML governance tools for Amazon SageMaker which simplifies access control and enhances transparency over your ML projects. Depending on your governance requirements, Data Science & Dev accounts can be merged into a single AWS account.
.` Hagay Lupesko VP Engineering, MosaicML | Expert in Generative AI Training and Inference, Former Leader at Meta AI and AWS In his role as VP of Engineering, Hagay Lupesko focuses on making generative AI training and inference efficient, fast, and accessible.
The number of annual data breaches gets higher each year. In 2012, records show there were 447 data breaches in the United States. Ten years later, in 2022, researchers recorded 1,800 cases of data compromise. million data records were leaked. In Q1 of 2023, as many as 6.41 You can connect with him on LinkedIn.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of data silos or the need to copy data between systems. Environments are the actual data infrastructure behind a project.
Diverse data amplifies the need for customizable cleaning and transformation logic to handle the quirks of different sources. In this post, we will explore building a reusable RAG data pipeline on LangChain —an open source framework for building applications based on LLMs—and integrating it with AWS Glue and Amazon OpenSearch Serverless.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content