This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
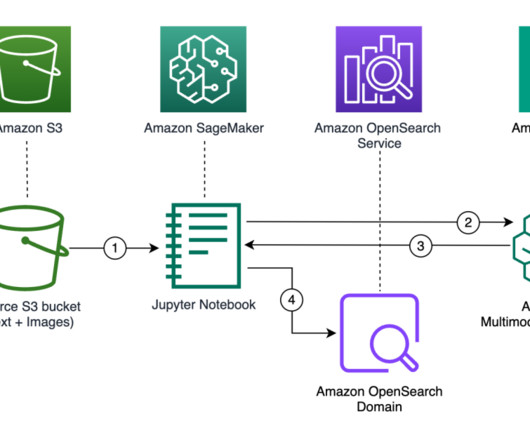
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
OpenSearch Service is the AWS recommended vector database for Amazon Bedrock. Its a fully managed service that you can use to deploy, operate, and scale OpenSearch on AWS. OpenSearch is a distributed open-source search and analytics engine composed of a search engine and vector database. An OpenSearch Service domain.
Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. The workflow steps are as follows: AWS Lambda running in your private VPC subnet receives the prompt request from the generative AI application.
At Amazon Web Services (AWS), we recognize that many of our customers rely on the familiar Microsoft Office suite of applications, including Word, Excel, and Outlook, as the backbone of their daily workflows. Using AWS, organizations can host and serve Office Add-ins for users worldwide with minimal infrastructure overhead.
Managing your Amazon Lex bots using AWS CloudFormation allows you to create templates defining the bot and all the AWS resources it depends on. AWS CloudFormation provides and configures those resources on your behalf, removing the risk of human error when deploying bots to new environments. Resources: # 1.
Athena uses the Athena Google BigQuery connector , which uses a pre-built AWS Lambda function to enable Athena federated query capabilities. This Lambda function retrieves the necessary BigQuery credentials (service account private key) from AWS Secrets Manager for authentication purposes. Choose Create data source. athenabigquery"."customer_churn"
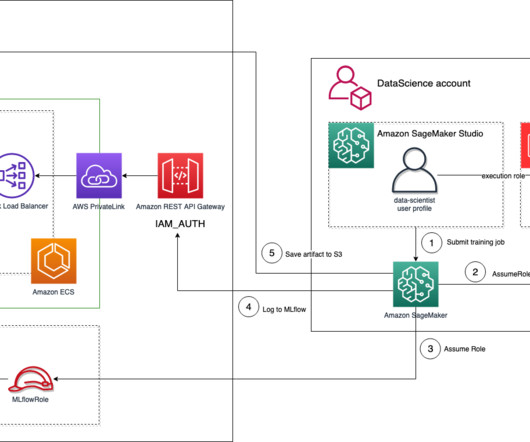
In a previous post , we discussed MLflow and how it can run on AWS and be integrated with SageMaker—in particular, when tracking training jobs as experiments and deploying a model registered in MLflow to the SageMaker managed infrastructure. To automate the infrastructure deployment, we use the AWS Cloud Development Kit (AWS CDK).
In addition to Amazon Bedrock, you can use other AWS services like Amazon SageMaker JumpStart and Amazon Lex to create fully automated and easily adaptable generative AI order processing agents. In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
Reduced operational overhead – The EMR Serverless integration with AWS streamlines big data processing by managing the underlying infrastructure, freeing up your team’s time and resources. Runtime roles are AWS Identity and Access Management (IAM) roles that you can specify when submitting a job or query to an EMR Serverless application.
As described in the AWS Well-Architected Framework , separating workloads across accounts enables your organization to set common guardrails while isolating environments. Organizations with a multi-account architecture typically have Amazon Redshift and SageMaker Studio in two separate AWS accounts. Select VPC Only , then choose Next.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Prerequisites To continue with the examples in this post, you need to create the required AWS resources.
That’s why our data visualization SDKs are database agnostic: so you’re free to choose the right stack for your application. There have been a lot of new entrants and innovations in the graph database category, with some vendors slowly dipping below the radar, or always staying on the periphery. can handle many graph-type problems.
Now, teams that collect sensor data signals from machines in the factory can unlock the power of services like Amazon Timestream , Amazon Lookout for Equipment , and AWS IoT Core to easily spin up and test a fully production-ready system at the local edge to help avoid catastrophic downtime events. Choose Create Timestream database.
For production use, it is recommended to use a more robust frontend framework such as AWS Amplify , which provides a comprehensive set of tools and services for building scalable and secure web applications. The process is straightforward, thanks to the user-friendly interface and step-by-step guidance provided by the AWS Management Console.
Configure AWS Identity and Access Management (IAM) roles for Snowflake and create a Snowflake integration. Prerequisites Prerequisites for this post include the following: An AWS account. An existing database within Snowflake. Do the same for the validation database. Import Snowflake directly into Canvas.
Learn more MLOps: What It Is, Why It Matters, and How to Implement It Designing the MLOps system on AWS It’s important to note that implementing MLOps practices can be challenging and may require significant investment in terms of time, resources, and expertise. The twin has permission to read and write (if needed) to it.
For provisioning Studio in your AWS account and Region, you first need to create an Amazon SageMaker domain—a construct that encapsulates your ML environment. Alternatively, you can adopt a naming standard for IAM role ARNs based on the AD group name and derive the IAM role ARN without needing to store the mapping in an external database.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. in 2012 is now widely referred to as ML’s “Cambrian Explosion.” The AWS P5 EC2 instance type range is based on the NVIDIA H100 chip, which uses the Hopper architecture. Work by Hinton et al.
For example, searching for the terms “How to orchestrate ETL pipeline” returns results of architecture diagrams built with AWS Glue and AWS Step Functions. The solution applies Amazon Rekognition Custom Labels to detect AWS service logos on architecture diagrams to allow the architecture diagrams to be searchable with service names.
Netezza Performance Server (NPS) has recently added the ability to access Parquet files by defining a Parquet file as an external table in the database. All SQL and Python code is executed against the NPS database using Jupyter notebooks, which capture query output and graphing of results during the analysis phase of the demonstration.
In this blog, we will review the steps to create Snowflake-managed Iceberg tables with AWS S3 as external storage and read them from a Spark or Databricks environment. Externally Managed Iceberg Tables – An external system, such as AWS Glue , manages the metadata and catalog. These tables support read-only access from Snowflake.
YouTube Introduction to Natural Language Processing (NLP) NLP 2012 Dan Jurafsky and Chris Manning (1.1) Deploy LLMs in production Deploy Model Azure — Use endpoints for inference — Azure Machine Learning | Microsoft Learn AWS + Huggingface — Exporting ?
In 2012, records show there were 447 data breaches in the United States. REGISTER NOW Mapping Uncovered Data All of the databases are identified. The data flow mapping process is used to help you take a couple of steps back to see the entire architecture and all the databases within it from a distance.
By harnessing the capabilities of generative AI, you can automate the generation of comprehensive metadata descriptions for your data assets based on their documentation, enhancing discoverability, understanding, and the overall data governance within your AWS Cloud environment. Fetch information for the database tables from the Data Catalog.
Since DataRobot was founded in 2012, we’ve been committed to democratizing access to the power of AI. DataRobot AI Cloud brings together any type of data from any source to give our customers a holistic view that drives their business: critical information in databases, data clouds, cloud storage systems, enterprise apps, and more.
You can use familiar AWS services for model development, generative AI, data processing, and analyticsall within a single, governed environment. These connections are stored in the AWS Glue Data Catalog (Data Catalog) and registered with Lake Formation, allowing you to create a federated catalog for each available data source.
In this blog post, we will showcase how IBM Consulting is partnering with AWS and leveraging Large Language Models (LLMs), on IBM Consulting’s generative AI-Automation platform (ATOM), to create industry-aware, life sciences domain-trained foundation models to generate first drafts of the narrative documents, with an aim to assist human teams.
The data for this track came from DementiaBank , an open database for the study of communication progression in dementia that combines data from different research studies. changes between 2003 and 2012). At IGC Pharma, Nestor plays a crucial role in integrating and harmonizing extensive Alzheimer's disease-related databases.
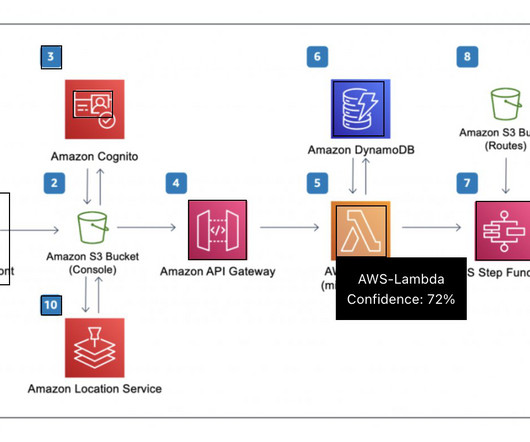
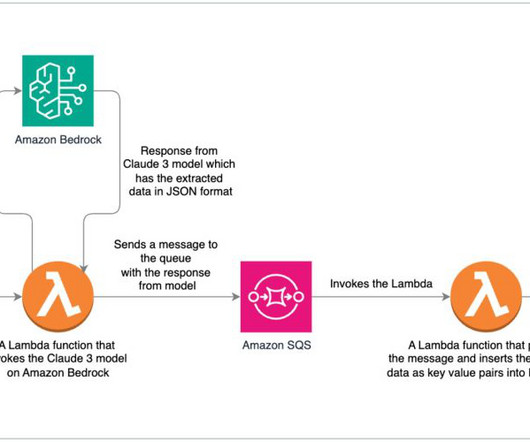
We demonstrate how to extract data from a scanned document and insert it into a database. The architecture consists of several AWS services seamlessly integrated with the Amazon Bedrock, enabling efficient and accurate extraction of data from scanned documents. Amazon DynamoDB is a fully managed, serverless, NoSQL database service.
The data might exist in various formats such as files, database records, or long-form text. An AI technique called embedding language models converts this external data into numerical representations and stores it in a vector database. This new data from outside of the LLM’s original training data set is called external data.
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets.
It helps ingest, structure, and retrieve information from databases, APIs, PDFs, and more, enabling the agent and RAG for AI applications. Prerequisites The solution has been tested in the AWS Region us-west-2. In this post, we demonstrate an example of building an agentic RAG application using the LlamaIndex framework.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content