This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Solution overview Implementing the solution consists of the following high-level steps: Set up your environment and the permissions to access Amazon HyperPod clusters in SageMaker Studio. You can now use SageMaker Studio to discover the SageMaker HyperPod clusters, and view cluster details and metrics.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
From vCenter, administrators can configure and control ESXi hosts, datacenters, clusters, traditional storage, software-defined storage, traditional networking, software-defined networking, and all other aspects of the vSphere architecture. VMware “clustering” is purely for virtualization purposes.
In this post, we walk through step-by-step instructions to establish a cross-account connection to any Amazon Redshift node type (RA3, DC2, DS2) by connecting the Amazon Redshift cluster located in one AWS account to SageMaker Studio in another AWS account in the same Region using VPC peering.
In this post, we discuss how an enterprise with multiple accounts can access a shared Amazon SageMaker HyperPod cluster for running their heterogenous workloads. Account A hosts the SageMaker HyperPod cluster. To access Account A’s EKS cluster as a user in Account B, you will need to assume a cluster access role in Account A.
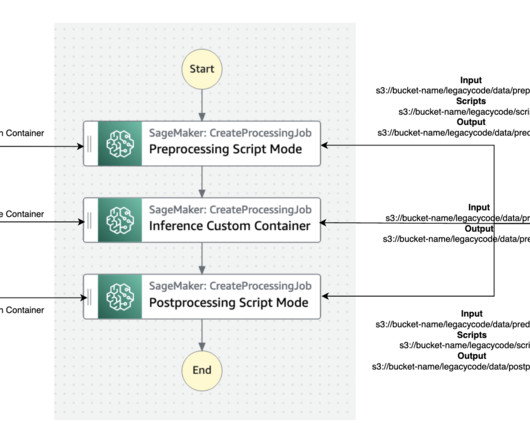
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
In 2012, Google boasted about its capabilities of using big data to create storytelling via interactive maps. Grouping radii can serve to visually demonstrate a cluster of comparative data within a particular location. The highly intuitive data interface provided by Google Maps can be very helpful.
With Amazon OpenSearch Serverless, you don’t need to provision, configure, and tune the instance clusters that store and index your data. For more information on managing credentials securely, see the AWS Boto3 documentation. In the Amazon OpenSearch Service console, choose Serverless Collections , then select your collection.
Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. In the processing job API, provide this path to the parameter of submit_jars to the node of the Spark cluster that the processing job creates. We attached the IAM role to the Redshift cluster that we created earlier.
A basic, production-ready cluster priced out to the low-six-figures. A company then needed to train up their ops team to manage the cluster, and their analysts to express their ideas in MapReduce. Plus there was all of the infrastructure to push data into the cluster in the first place. Goodbye, Hadoop. And it was good.
of persons present’ for the sustainability committee meeting held on 5th April, 2012? His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. WASHINGTON, D. 20036 1128 SIXTEENTH ST., WASHINGTON, D.
Usually, if the dataset or model is too large to be trained on a single instance, distributed training allows for multiple instances within a cluster to be used and distribute either data or model partitions across those instances during the training process. Each account or Region has its own training instances.
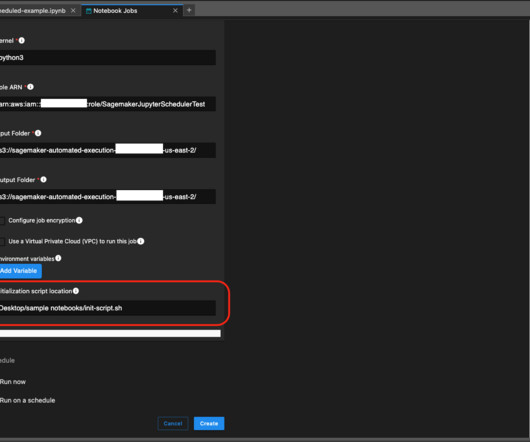
In addition to the IAM user and assumed role session scheduling the job, you also need to provide a role for the notebook job instance to assume for access to your data in Amazon Simple Storage Service (Amazon S3) or to connect to Amazon EMR clusters as needed.
Cost-efficiency and infrastructure optimization By moving away from GPU-based clusters to Fargate, our monthly infrastructure costs are now 78.47% lower, and our per-question costs have reduced by 87.6%. With a decade of experience at Amazon, having joined in 2012, Kshitiz has gained deep insights into the cloud computing landscape.
Use Cases : Sentiment Analysis, Machine Translation, Named Entity Recognition Significant papers: “ Learning word embeddings efficiently with noise-contrastive estimation ” by Mnih and Hinton (2012) “Sequence to sequence learning with neural machine translation” by Sutskever et al. 2020) “GPT-4 Technical report ” by Open AI.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. in 2012 is now widely referred to as ML’s “Cambrian Explosion.” As with leading LLMs, time series FMs are likely to be successfully trained on large clusters of PBAs. Work by Hinton et al.
Cluster resources are provisioned for the duration of your job, and cleaned up when a job is complete. The processing container image can either be a SageMaker built-in image or a custom image that you provide. The underlying infrastructure for a Processing job is fully managed by SageMaker.
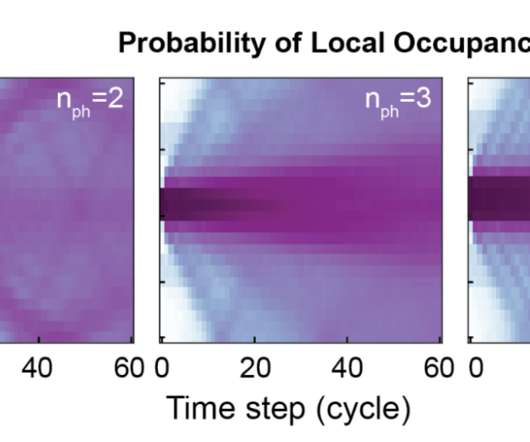
A group of photons initially clustered on neighboring sites will evolve into a superposition of all possible paths each photon might have taken. Among all the possible configuration paths, the only possible scenario that survives is the configuration in which all photons remain clustered together in a bound state.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., 2012; Otsu, 1979; Long et al., Methodology In this study, we used the publicly available PASCAL VOC 2012 dataset (Everingham et al., References: Arbeláez, P.,
” First release: 2012 Format: An open-source, multi-model (property graph, document and key-value) database with hosted and local options Top 3 advantages: Native multi-model – 3 database models in one, reducing costs of ownership and tech stack complexity.
The only problem is that the list really contains two clusters of words: one associated with the legal meaning of “pleaded”, and one for the more general sense. Sorting out these clusters is an area of active research. Hardware : Intel i7-3770 (2012) Efficiency is a major concern for NLP applications.
For Secret type , choose Credentials for Amazon Redshift cluster. Choose the Redshift cluster associated with the secrets. or later image versions. Complete the following steps: On the Secrets Manager console, choose Store a new secret. Enter the credentials used to log in to access Amazon Redshift as a data source.
The tutorial also recommends the use of Brown cluster features, and case normalization features, as these make the model more robust and domain independent. I use greedy decoding, not beam search; I use the arc-eager transition system; I use the Goldberg and Nivre (2012) dynamic oracle. spaCy’s tagger makes heavy use of these features.
And in 2012 we introduced Quantity to represent quantities with units in the Wolfram Language. but with things like clustering). Meanwhile, having realized that date arithmetic is involved in the “inner loop” of certain computations, we optimized it—achieving a more than 100x speedup in Version 14.0.
In the Redshift navigation pane, you can also see the datashare created between the source and the target cluster. In this case, because the data is shared in the same account but between different clusters, SageMaker Unified Studio creates a view in the target database and permissions are granted on the view.
The final sub-models use broad semantic clustering, an ensemble of the provided acoustic features, a Whisper classification fine-tune, and a contrastive Whisper fine-tune, designed to focus the model on identifying features independent of age, gender, and semantic group. Cluster 0 was in English and included many people talking to an Alexa.
In 2012, with the permission of the police, Janette used a magnifying glass to find where several hairs came together in a cluster. As the death mask had been molded directly off the Somerton Man’s head, neck, and upper body, some of the man’s hair was embedded in the plaster of Paris—a potential DNA gold mine.
Amazon Bedrock Knowledge Bases provides industry-leading embeddings models to enable use cases such as semantic search, RAG, classification, and clustering, to name a few, and provides multilingual support as well.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content