This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In 2012, Harvard Business Review declared the data scientist the sexiest job of the 21st century. Heres what we knew at the time: big data was (and still is to this day) an enormous opportunity to make new discoveries. In the data and AI era Will dataengineering reign supreme?
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. Data Lakes : It supports MS Azure Blob Storage.
Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem. In regards to the challenge of operationalizing machine learning, this problem prompted a surge of investment to find a solution.
In fact, you may have even heard about IDC’s new Global DataSphere Forecast, 2021-2025 , which projects that global data production and replication will expand at a compound annual growth rate of 23% during the projection period, reaching 181 zettabytes in 2025. zettabytes of data in 2020, a tenfold increase from 6.5
He then earned a masters degree in operations research in 2012 from Columbia. Each one represents a specific skill: exploratory data analysis and visualization, data storytelling, statistics, programming, experimentation, modeling, machine learning operations, and dataengineering.
Additionally, make sure you scope down the resources in the runtime policies to adhere to the principle of least privilege. { "Version": "2012-10-17", "Statement": [ { "Sid": "ReadAccessForEMRSamples", "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::*.elasticmapreduce",
Process Mining Tools, die als pure Process Mining Software gestartet sind Hierzu gehört Celonis, das drei-köpfige und sehr geschäftstüchtige Gründer-Team, das ich im Jahr 2012 persönlich kennenlernen durfte. Reduzierte Personalkosten , sind oft dann gegeben, wenn interne DataEngineers verfügbar sind, die die Datenmodelle intern entwickeln.
He develops and codes cloud native solutions with a focus on big data, analytics, and dataengineering. He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to.NET, Java, and Python.
Key takeaways The demand for Data Science professionals is going to increase. There has been a 650% rise in the analytics domain since 2012. Employment of data scientists is projected to grow 35% from 2022 to 2032 The average salary of a Data Scientist in India is around ₹ 3.9 Lakhs Benefits of studying Data Science 1.
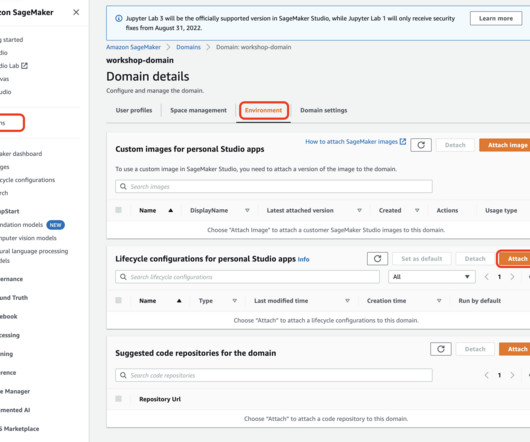
In addition to dataengineers and data scientists, there have been inclusions of operational processes to automate & streamline the ML lifecycle. For the AWS IAM policy configured with the correct credentials, make sure that you have permissions to create, edit, and delete model cards within Amazon SageMaker.
Enterprises were collecting vast ecosystems of data, and began regarding them, for the first time, as worlds worthy of exploration. The data scientist. In 2012 Davenport and Patil declared the data scientist was “ The Sexiest Job of the 21st Century.” programs in Information Science and Data Analytics.
Around 2012 to 2014, developers proposed updating these modules, but were told to use third party libraries instead. Postgres Replication Issue There is an update on work to address lag in Postgres replication for the dataengineering team. However, over time these modules became outdated.
In addition to dataengineers and data scientists, there have been inclusions of operational processes to automate & streamline the ML lifecycle. For the AWS IAM policy configured with the correct credentials, make sure that you have permissions to create, edit, and delete model cards within Amazon SageMaker.
Immuta’s natural language policy (NLP) builder allows your business users to define who gets access to data and what they can see when they run queries, with no technical expertise required. This means that your dataengineering teams won’t be the bottleneck that limits the amount of data used to generate insights.
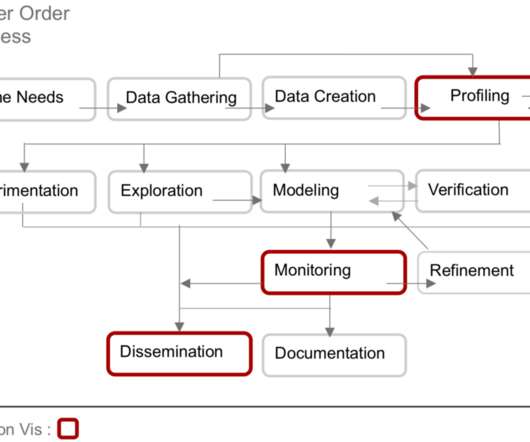
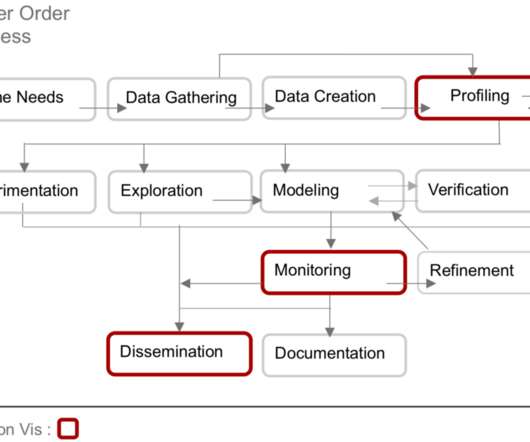
You may have noticed the rise of the dataengineer, for example, as a distinct but still adjacent data science role. As data science work grew in complexity, data scientists became less generalized and more specialized, often engaged in specific aspects of data science work.
You may have noticed the rise of the dataengineer, for example, as a distinct but still adjacent data science role. As data science work grew in complexity, data scientists became less generalized and more specialized, often engaged in specific aspects of data science work.
An AI technique called embedding language models converts this external data into numerical representations and stores it in a vector database. RAG introduces additional dataengineering requirements: Scalable retrieval indexes must ingest massive text corpora covering requisite knowledge domains.
This integration eliminates the need for additional data movement or complex integrations, enabling you to focus on building and deploying ML models without the overhead of dataengineering tasks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content