This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Back in 2012, Harvard Business Review called data scientists “the sexiest job of the 21st century.” That may or may not be true, but I do believe that one of the hardest jobs in the latter half of this decade is that of the executive responsible for developing and implementing AI strategy in the enterprise.
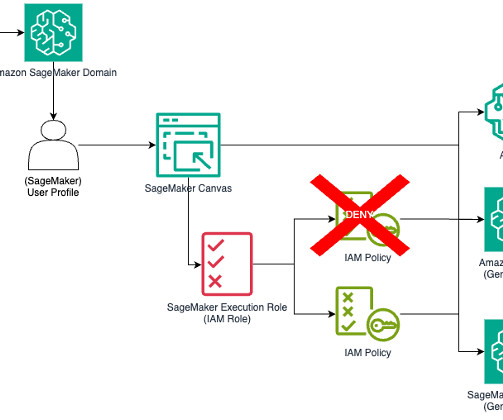
Limit access to all Amazon Bedrock models To restrict access to all Amazon Bedrock models, you can modify the SageMaker role to explicitly deny these APIs. This makes sure no user can invoke any Amazon Bedrock model through SageMaker Canvas. This way, users can only invoke the allowed models.
Best practices for datapreparation The quality and structure of your training data fundamentally determine the success of fine-tuning. Our experiments revealed several critical insights for preparing effective multimodal datasets: Data structure You should use a single image per example rather than multiple images.
This historical sales data covers sales information from 2010–02–05 to 2012–11–01. So let’s filter out and keep only a handful of data to perform the analysis. DataPreparation It’s time me filter out the unnecessary records to make it easier to visualize the dataset. df['Store'] = df['Store'].astype('category')df['Dept']
We’re excited to announce Amazon SageMaker Data Wrangler support for Amazon S3 Access Points. In this post, we walk you through importing data from, and exporting data to, an S3 access point in SageMaker Data Wrangler.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. elasticmapreduce", "arn:aws:s3:::*.elasticmapreduce/*" elasticmapreduce", "arn:aws:s3:::*.elasticmapreduce/*"
SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment. of persons present’ for the sustainability committee meeting held on 5th April, 2012? WASHINGTON, D. 20036 1128 SIXTEENTH ST., WASHINGTON, D.
Both the training and validation data are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket for model training in the client account, and the testing dataset is used in the server account for testing purposes only. Details of the datapreparation code are in the following notebook.
Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
Since DataRobot was founded in 2012, we’ve been committed to democratizing access to the power of AI. We’re building a platform for all users: data scientists, analytics experts, business users, and IT. Let’s dive into each of these areas and talk about how we’re delivering the DataRobot AI Cloud Platform with our 7.2
Option C: Use SageMaker Data Wrangler SageMaker Data Wrangler allows you to import data from various data sources including Amazon Redshift for a low-code/no-code way to prepare, transform, and featurize your data.
AlexNet is a more profound and complex CNN architecture developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton in 2012. The data should be split into training, validation, and testing sets. It has eight layers, five of which are convolutional and three fully linked.
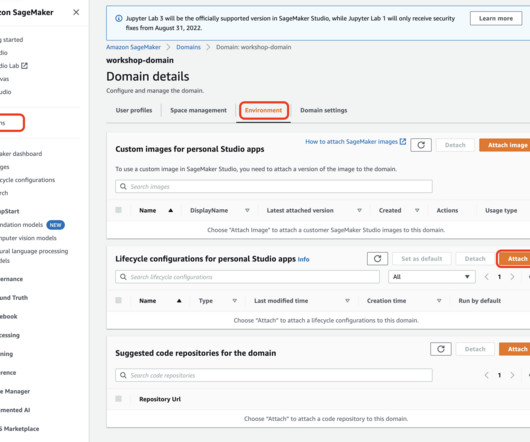
He is focused on building interactive ML solutions which simplify data processing and datapreparation journeys. Sumedha Swamy is a Principal Product Manager at Amazon Web Services where he leads SageMaker Studio team in its mission to develop IDE of choice for data science and machine learning. or later image versions.
Starting from AlexNet with 8 layers in 2012 to ResNet with 152 layers in 2015 – the deep neural networks have become deeper with time. It requires significant effort in terms of datapreparation, exploration, processing, and experimentation, which involves trying out algorithms and hyperparameters.
Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics. in 2012 is now widely referred to as ML’s “Cambrian Explosion.” The union of advances in hardware and ML has led us to the current day. Work by Hinton et al.
However, you can also test this by using the Custom project profile by selecting specific blueprints such as LakehouseCatalog and LakeHouseDatabase for scenarios where the business unit doesnt have their own data warehouse. Solution walkthrough (Scenario 1) The first step focuses on preparing the data for each data source for unified access.
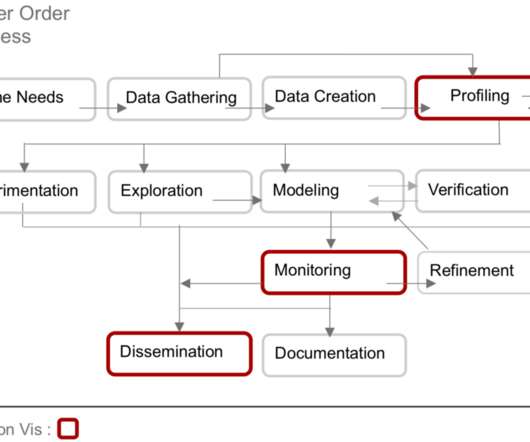
As data science work grew in complexity, data scientists became less generalized and more specialized, often engaged in specific aspects of data science work. as early as 2012 already identified this trend, which has only accelerated over time. Interviews conducted by Harris et al.
As data science work grew in complexity, data scientists became less generalized and more specialized, often engaged in specific aspects of data science work. as early as 2012 already identified this trend, which has only accelerated over time. Interviews conducted by Harris et al.
Job title history of data scientist The title “data scientist” gained prominence in 2008 when companies like Facebook and LinkedIn utilized it in corporate job descriptions. Citizen Data Scientist: Uses existing analytics tools but may lack formal training and earn a salary more aligned with general activities.
This minimizes the complexity and overhead associated with moving data between cloud environments, enabling organizations to access and utilize their disparate data assets for ML projects. You can use SageMaker Canvas to build the initial datapreparation routine and generate accurate predictions without writing code.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content