This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enter AnalyticsCreator AnalyticsCreator, a powerful tool for data management, brings a new level of efficiency and reliability to the CI/CD process. It offers full BI-Stack Automation, from source to datawarehouse through to frontend. It supports a holistic data model, allowing for rapid prototyping of various models.
Amazon Redshift is a fully managed, fast, secure, and scalable cloud datawarehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a datawarehouse such as Amazon Redshift. On the Select trusted entity page, select Custom trust policy.
Solution overview With SageMaker Studio JupyterLab notebook’s SQL integration, you can now connect to popular data sources like Snowflake, Athena, Amazon Redshift, and Amazon DataZone. For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. Conclusion In this post, we demonstrated an end-to-end data and ML flow from a Redshift datawarehouse to SageMaker.
Netezza Performance Server (NPS) has recently added the ability to access Parquet files by defining a Parquet file as an external table in the database. This allows data that exists in cloud object storage to be easily combined with existing datawarehousedata without data movement. The data definition.
LDP is a comprehensive tool that can be used to replicate data from a variety of sources, including databases, files, and applications. Windows Server: 2012 R2, 2016, 2019 In this blog, we will do a deep dive into understanding LDP Architecture. Fivetran LDP is compatible with popular operating systems like: AIX_6.1-POWERPC-64BIT
LDP (or HVR) is a comprehensive tool that can be used to replicate data from a variety of sources, including databases, files, and applications. Windows Server: 2012 R2, 2016, 2019 In this blog, we will do a deep dive into understanding LDP (HVR) Architecture. POWERPC-64BIT (AIX: 6.1, Linux (x86-64 bit) based on GLIBC 2.12
In this blog, we’ll explore the compelling reasons behind transitioning from Teradata to the cutting-edge Snowflake Data Cloud. Teradata was founded in 1979, and it was a revolutionary DBMS (Database Management System) capable of parallel processing with more than one processor at the same time. What is Teradata?
December 2012: Alation forms and goes to work creating the first enterprise data catalog. Later, in its inaugural report on data catalogs, Forrester Research recognizes that “Alation started the MLDC trend.”. Here’s a timeline view of what the market has said about Alation since our founding: Timeline: 10 Years of Alation.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. The existing Data Catalog becomes the Default catalog (identified by the AWS account number) and is readily available in SageMaker Lakehouse.
The workflow includes the following steps: Within the SageMaker Canvas interface, the user composes a SQL query to run against the GCP BigQuery datawarehouse. Athena returns the queried data from BigQuery to SageMaker Canvas, where you can use it for ML model training and development purposes within the no-code interface.
This new data from outside of the LLM’s original training data set is called external data. The data might exist in various formats such as files, database records, or long-form text. You can build and manage an incremental data pipeline to update embeddings on Vectorstore at scale.
Back in 2016 I was trying to explain to software engineers how to think about machine learning models from a software design perspective; I told them that they should think of a database. Both serve as a means of storing representations of historical data, which can later be queried. Library, primitive data storage solution.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






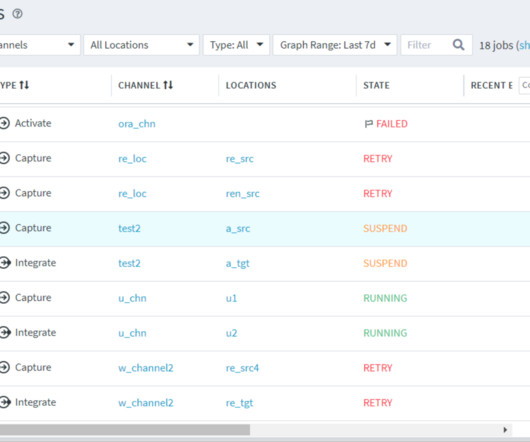
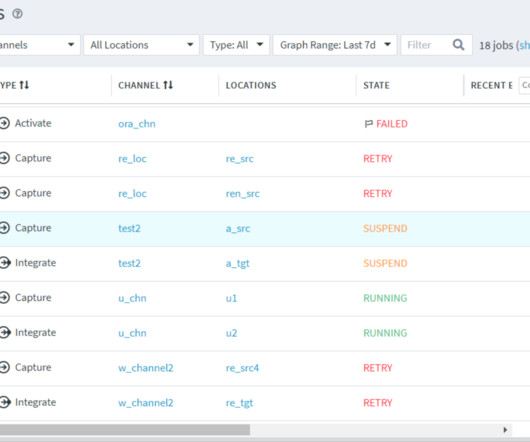












Let's personalize your content