
Your Mouse Is a Database (2012)
Hacker News
APRIL 7, 2025
Comments (..)


Data Science Blog
MAY 20, 2024
It also supports a wide range of data warehouses, analytical databases, data lakes, frontends, and pipelines/ETL. Support for Various Data Warehouses and Databases : AnalyticsCreator supports MS SQL Server 2012-2022, Azure SQL Database, Azure Synapse Analytics dedicated, and more.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
APRIL 24, 2025
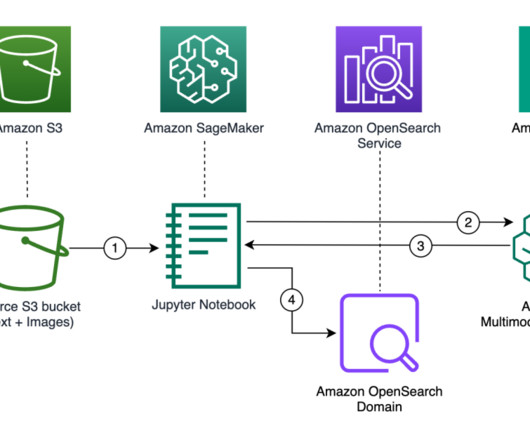
OpenSearch Service is the AWS recommended vector database for Amazon Bedrock. OpenSearch is a distributed open-source search and analytics engine composed of a search engine and vector database. To learn more, see Improve search results for AI using Amazon OpenSearch Service as a vector database with Amazon Bedrock.

AWS Machine Learning Blog
NOVEMBER 13, 2024
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. To do so, you can use a vector database. Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME)
Hacker News
FEBRUARY 24, 2023
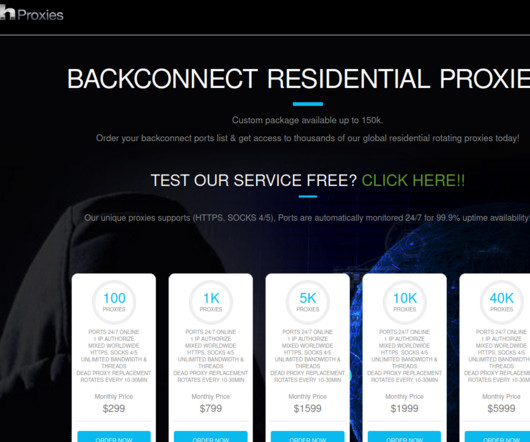
BHProxies has authored 129 posts on Black Hat World since 2012, and their last post on the forum was in December 2022. BHProxies initially was fairly active on Black Hat World between May and November 2012, after which it suddenly ceased all activity. The website BHProxies[.]com

Hacker News
FEBRUARY 5, 2023
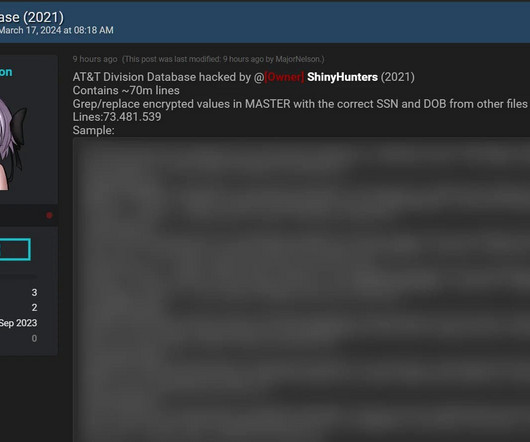
From that story: “Among those who grabbed a copy of the database was Antti Kurittu , a team lead at Nixu Corporation and a former criminal investigator. There were also other projects and databases.” The DDoS-for-hire service allegedly operated by Kivimäki in 2012. Kivimäki was 15 years old at the time.

AWS Machine Learning Blog
OCTOBER 30, 2023
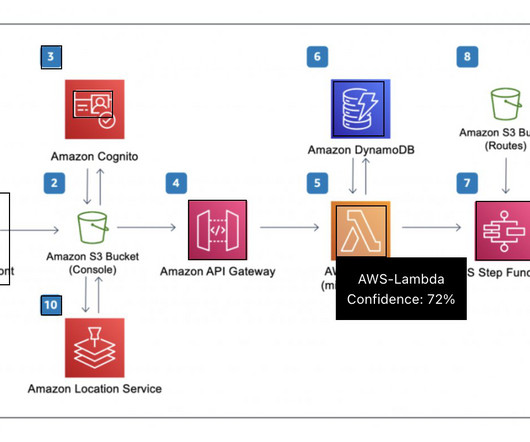
When building such generative AI applications using FMs or base models, customers want to generate a response without going over the public internet or based on their proprietary data that may reside in their enterprise databases. You’re redirected to the IAM console. Currently, the VPC endpoint policy is set to Allow.

Expert insights. Personalized for you.































Let's personalize your content