This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It also supports a wide range of data warehouses, analytical databases, data lakes, frontends, and pipelines/ETL. Support for Various Data Warehouses and Databases : AnalyticsCreator supports MS SQL Server 2012-2022, Azure SQL Database, Azure Synapse Analytics dedicated, and more. pipelines, Azure Data Bricks.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
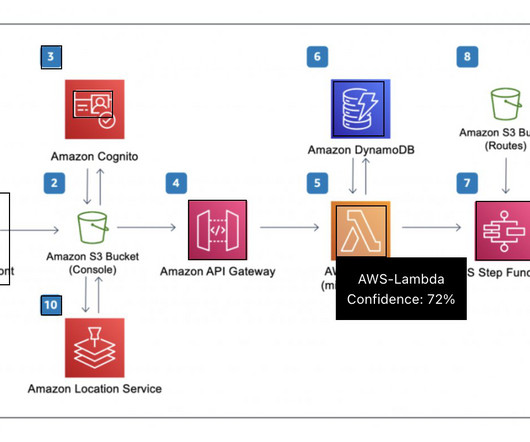
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. For example, searching for the terms “How to orchestrate ETL pipeline” returns results of architecture diagrams built with AWS Glue and AWS Step Functions. join(", "), }; }).catch((error)
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content