This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We will start the series by diving into the historical background of embeddings that began from the 2013 Word2Vec paper. Here’s a guide to choosing the right vector embedding model Importance of Vector Databases in Vector Search Vector databases are the backbone of efficient and scalable vector search.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
Face detection algorithms based on geometric models, such as the Haar cascades model, or machine learning-based approaches, such as convolutional neural networks (CNNs), have been used to perform this task. Algorithms such as fiducial landmark detection and shape vector representation have been employed to extract these descriptors.
Fast Company wrote about this back in 2013 when they said that Big Data is Rewriting Hollywood Scripts. Tools like this use complex data-driven algorithms to come up with the best deck examples for aspiring screenwriters. There is a large database that can help you find what you are looking for.
Improving Operations and Infrastructure Taipy The inspiration for this open-source software for Python developers was the frustration felt by those who were trying, and struggling, to bring AI algorithms to end-users. Making Data Observable Bigeye The quality of the data powering your machine learning algorithms should not be a mystery.
One of my pet peeves is rooted in Sean Parents 2013 talk at GoingNative, Seasoning C++ where he advocated for no raw loops. Otherwise, if you write code where you also do some network calls or read from the database or from the filesystem, these differences are negligible and you should go with the version that you find the most readable.
Prerequisites For this post, the administrator needs the following prerequisites: A Snowflake user with administrator permission to create a Snowflake virtual warehouse, user, and role, and grant access to this user to create a database. The dataset includes credit card transactions in September 2013 made by European cardholders.
The forecasting algorithm uses gradient boosting to model data and the rolling average of historical data to help predict trends. This low-code solution lets you use your existing Snowflake data and easily create a visualization to predict the future of your sales, taking into account unlimited data points.
Here are a few reasons why an agent needs tools: Access to external resources: Tools allow an agent to access and retrieve information from external sources, such as databases, APIs, or web scraping. This includes cleaning and transforming data, performing calculations, or applying machine learning algorithms.
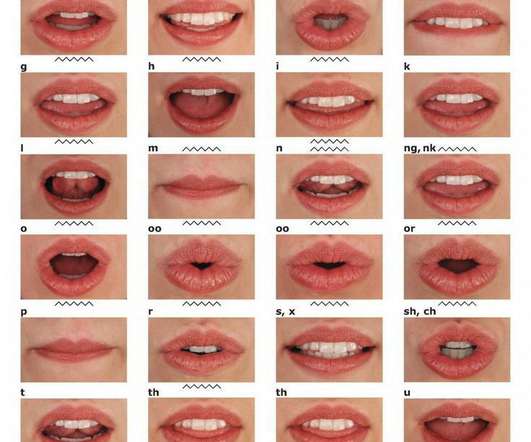
17] “ LipNet ” introduces the first approach for an end-to-end lip reading algorithm at sentence level. 27] LipNet also makes use of an additional algorithm typically used in speech recognition systems — a Connectionist Temporal Classification (CTC) output. Thus the algorithm is alignment-free. Vive Differentiable Programming!
And so were in a position to compare the results of human effort (aided, in many cases, by systematic search) with what we can automatically do by the algorithmic process of adaptive evolution. Butas was actually already realized in the mid-1990sits still possible to use algorithmic methods to fill in pieces of patterns.
Summary of approach : Using a downsampling method with ChatGPT and ML techniques, we obtained a full NEISS dataset across all accidents and age groups from 2013-2022 with six new variables: fall/not fall, prior activity, cause, body position, home location, and facility. What motivated you to participate? : race and sex).
A generative AI foundation can provide primitives such as models, vector databases, and guardrails as a service and higher-level services for defining AI workflows, agents and multi-agents, tools, and also a catalog to encourage reuse. Considerations here are choice of vector database, optimizing indexing pipelines, and retrieval strategies.
These tools leverage advanced algorithms and methodologies to process large datasets, uncovering valuable insights that can drive strategic decision-making. uses Hadoop to process over 24 petabytes of data daily, enabling them to improve their search algorithms and ad targeting. Use Cases : Yahoo!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content