This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
sktime — Python Toolbox for MachineLearning with Time Series Editor’s note: Franz Kiraly is a speaker for ODSC Europe this June. Be sure to check out his talk, “ sktime — Python Toolbox for MachineLearning with Time Series ,” there! How to maintain it in a private code base, or contribute to sktime’s algorithm library.
We will start the series by diving into the historical background of embeddings that began from the 2013 Word2Vec paper. They use specialized indexing techniques, like Approximate Nearest Neighbor (ANN) algorithms, to speed up searches without compromising accuracy. She specializes in community engagement and education.
The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. The data span a period of 18 years, including ~35 million reviews up to March 2013. But often, these methods fail on more complex tasks.
Cloud Programming Simplified: A Berkeley View on Serverless Computing (2019) – Serverless computing is very popular nowadays and this article covers some of the limitations.
Machinelearning, computer vision, and signal processing techniques have been extensively explored to address this problem by leveraging information from various multimedia data sources. Artificial intelligence techniques, particularly computer vision and machinelearning, have led to significant advancements in this field.
Fortunately, new predictive analytics algorithms can make this easier. The financial industry is becoming more dependent on machinelearning technology with each passing day. Machinelearning has helped reduce man-hours, increase accuracy and minimize human bias. For further information explore quantum code.
Researchers are, for instance, using machinelearning to investigate methods of debris removal and reuse. These] algorithm[s] assume that tomorrow looks like today,” Jah says. “So, This way, she adds, “algorithms can better adapt to the changing spatial environment.”
These technologies leverage sophisticated algorithms to process vast amounts of medical data, helping healthcare professionals make more accurate decisions. By leveraging machinelearningalgorithms, AI systems can analyze medical images, such as X-rays, MRIs, and CT scans, with remarkable accuracy and speed.
Artificial intelligence and machinelearning are no longer the elements of science fiction; they’re the realities of today. This popularity is primarily due to the spread of big data and advancements in algorithms. Machinelearningalgorithms are designed to uncover connections and patterns within data.
Many organizations are implementing machinelearning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. Because this data is across organizations, we use federated learning to collate the findings. He entered the big data space in 2013 and continues to explore that area.
Improving Operations and Infrastructure Taipy The inspiration for this open-source software for Python developers was the frustration felt by those who were trying, and struggling, to bring AI algorithms to end-users. Cloudera For Cloudera, it’s all about machinelearning optimization.
Photo by Ian Taylor on Unsplash This article will comprehensively create, deploy, and execute machinelearning application containers using the Docker tool. It will further explain the various containerization terms and the importance of this technology to the machinelearning workflow. What is Docker?
For example, image classification, image search engines (also known as content-based image retrieval, or CBIR), simultaneous localization and mapping (SLAM), and image segmentation, to name a few, have all been changed since the latest resurgence in neural networks and deep learning. 2015 ), SSD ( Fei-Fei et al., probability).
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machinelearning (ML) workflows without writing any code. Choose Add step.
Basically crack is a visible entity and so image-based crack detection algorithms can be adapted for inspection. Deep learningalgorithms can be applied to solving many challenging problems in image classification. Deep learningalgorithms can be applied to solving many challenging problems in image classification.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machinelearning (Arbeláez et al., The MBD algorithm then searches for a subset of nodes (i.e., 2013; Goodfellow et al., 2012; Otsu, 1979; Long et al., 2018; Sitawarin et al.,
Iris was designed to use machinelearning (ML) algorithms to predict the next steps in building a data pipeline. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machinelearning.
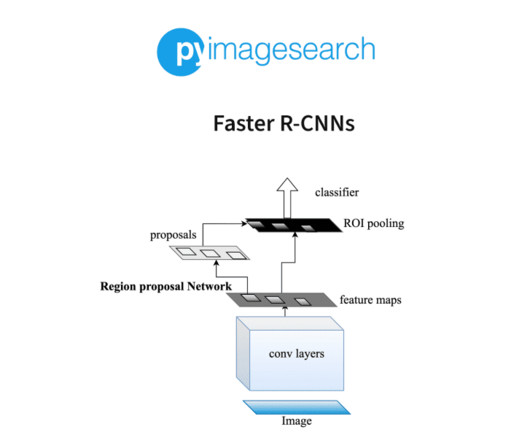
In the Beginning The first object detection algorithm is difficult to pinpoint to a single specific algorithm, as the field of object detection has evolved over several decades with numerous contributions. The development of region-based convolutional neural networks (R-CNN) in 2013 marked a crucial milestone.
In this three-part series, we present a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machinelearning (ML) services for a mortgage underwriting use case. You can use the prediction to trigger business rules in relation to underwriting decisions.
Cortex ML is Snowflake’s newest feature, added to enhance the ease of use and low-code functionality of your business’s machinelearning needs. The forecasting algorithm uses gradient boosting to model data and the rolling average of historical data to help predict trends. What is Cortex ML, and Why Does it Matter?
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machinelearning to responsible AI. Another project, SynthID , helps to identify and watermark AI-generated images.
Numerous movies have been produced and made that enables you to understand the ways in which Artificial Intelligence, MachineLearning, Data and Information have played crucial roles. The Matrix is mainly a world simulated for creating and controlling machines, which use data and algorithms to maintain the illusion of reality.
Word2Vec, a widely-adopted NLP algorithm has proven to be an efficient and valuable tool that is now applied across multiple domains, including recommendation systems. While numerous techniques have been explored, methods harnessing natural language processing (NLP) have demonstrated strong performance.
From 2013 to 2023, he divided his time working for Google (Google Brain) and the University of Toronto, before publicly announcing his departure from Google in May 2023 citing concerns about the risks of artificial intelligence (AI) technology. Hinton is viewed as a leading figure in the deep learning community.
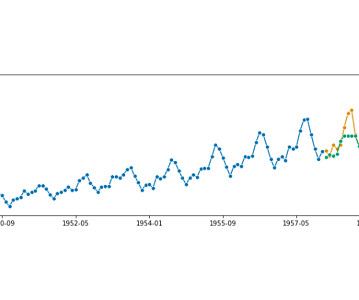
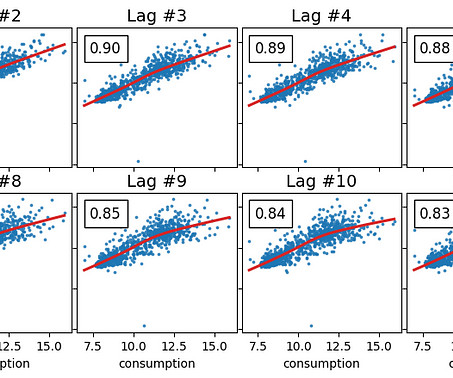
As described in the previous article , we want to forecast the energy consumption from August of 2013 to March of 2014 by training on data from November of 2011 to July of 2013. Experiments Before moving on to the experiments, let’s quickly remember what’s our task.
This includes cleaning and transforming data, performing calculations, or applying machinelearningalgorithms. Hinton is viewed as a leading figure in the deep learning community. Data processing and manipulation: Tools provide the necessary functionality for an agent to process and manipulate data.
If you think about simple ingredients in the “cooking show” of AI—models, algorithms, and data—a lot of the models and algorithms have gotten a lot more black box; a lot more commoditized; frankly, available in the most positive sense. Yes, people were aware of data science, they were aware of machinelearning.
The repository includes embedding algorithms, such as Word2Vec, GloVe, and Latent Semantic Analysis (LSA), to use with their PIP loss implementation. As such, I’ve adapted and converted the simplest algorithm (LSA) and PIP loss implementations with PyTorch and guided comments for more flexibility. Dosovitskiy, A., Kolesnikov, A.,
If you think about simple ingredients in the “cooking show” of AI—models, algorithms, and data—a lot of the models and algorithms have gotten a lot more black box; a lot more commoditized; frankly, available in the most positive sense. Yes, people were aware of data science, they were aware of machinelearning.
Finally, one can use a sentence similarity evaluation metric to evaluate the algorithm. One such evaluation metric is the Bilingual Evaluation Understudy algorithm, or BLEU score. The idea of sampling an attention trajectory as an estimation was taken from a Reinforcement Learningalgorithm called REINFORCE[88].
The arrival of Deep Learning It is with this point that we introduce recent work from Assael et al. 17] “ LipNet ” introduces the first approach for an end-to-end lip reading algorithm at sentence level. Deep Learning est en train de mourir. Thus the algorithm is alignment-free. Vive Differentiable Programming! [27]
VAEs were introduced in 2013 by Diederik et al. They extended the idea of autoencoders to learn useful data distributions. It serves as a direct drop-in replacement for the original Fashion-MNIST dataset for benchmarking machinelearningalgorithms, with the benefit of being more representative of the actual data tasks and challenges.
It includes AI, Deep Learning, MachineLearning and more. High Demand for Data Scientists: Data Science roles have grown over 250% since 2013, with salaries reaching $153k/year. AI and MachineLearning Integration: AI-driven Data Science powers industries like healthcare, e-commerce, and entertainment34.
And so were in a position to compare the results of human effort (aided, in many cases, by systematic search) with what we can automatically do by the algorithmic process of adaptive evolution. Butas was actually already realized in the mid-1990sits still possible to use algorithmic methods to fill in pieces of patterns.
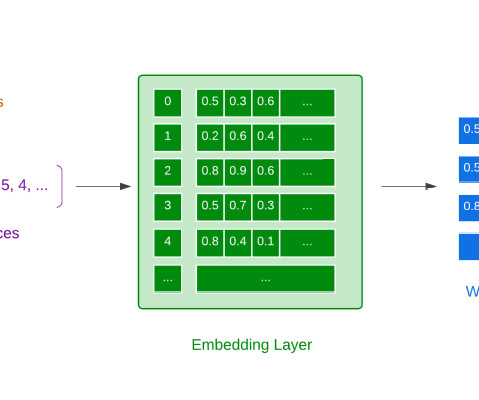
Word embeddings Visualisation of word embeddings in AI Distillery Word2vec is a popular algorithm used to generate word representations (aka embeddings) for words in a vector space. For instance, consider the sentence “ I like machinelearning ” and a context window of size 1. References Harris, Z. Distributional structure.
Anand, who began as an analyst in 2013, was promoted to assistant vice president in 2015. As an assistant vice president, he developed data science and machinelearning models to price bonds more accurately. The existing algorithms were not efficient. There are eight of what he calls spokes in data science.
In the Unsupervised Wisdom Challenge , participants were tasked with identifying novel, effective methods of using unsupervised machinelearning to extract insights about older adult falls from narrative medical record data. I enjoy participating in machinelearning/data-science challenges and have been doing it for a while.
These tools leverage advanced algorithms and methodologies to process large datasets, uncovering valuable insights that can drive strategic decision-making. uses Hadoop to process over 24 petabytes of data daily, enabling them to improve their search algorithms and ad targeting. Use Cases : Yahoo!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content