This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
sktime — Python Toolbox for Machine Learning with Time Series Editor’s note: Franz Kiraly is a speaker for ODSC Europe this June. Be sure to check out his talk, “ sktime — Python Toolbox for Machine Learning with Time Series ,” there! Welcome to sktime, the open community and Python framework for all things time series.
This post explains how transition-based dependency parsers work, and argues that this algorithm represents a break-through in natural language understanding. A concise sample implementation is provided, in 500 lines of Python, with no external dependencies. This post was written in 2013.
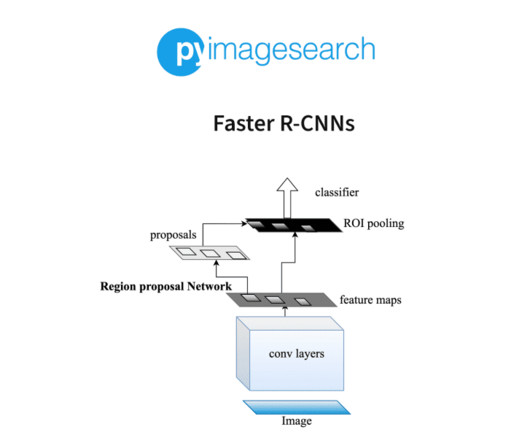
One of the most popular deep learning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al. Since then, the R-CNN algorithm has gone through numerous iterations, improving the algorithm with each new publication and outperforming traditional object detection algorithms (e.g.,
Improving Operations and Infrastructure Taipy The inspiration for this open-source software for Python developers was the frustration felt by those who were trying, and struggling, to bring AI algorithms to end-users. Blueprint’s tools and services allow organizations to quickly obtain decision-guiding insights from your data.
I wrote this blog post in 2013, describing an exciting advance in natural language understanding technology. Today, almost all high-performance parsers are using a variant of the algorithm described below (including spaCy). It’s now possible for a tiny Python implementation to perform better than the widely-used Stanford PCFG parser.
Basically crack is a visible entity and so image-based crack detection algorithms can be adapted for inspection. Deep learning algorithms can be applied to solving many challenging problems in image classification. Deep learning algorithms can be applied to solving many challenging problems in image classification. Yi, and J.-K.
The short story is, there are no new killer algorithms. The way that the tokenizer works is novel and a bit neat, and the parser has a new feature set, but otherwise the key algorithms are well known in the recent literature. Some might also wonder how I get Python code to run so fast.
Use a Python notebook to invoke the launched real-time inference endpoint. Basic knowledge of Python, Jupyter notebooks, and ML. The dataset includes credit card transactions in September 2013 made by European cardholders. For Training method and algorithms , select Auto. Choose Add step. Choose Dimensionality Reduction.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., Understanding the robustness of image segmentation algorithms to adversarial attacks is critical for ensuring their reliability and security in practical applications.
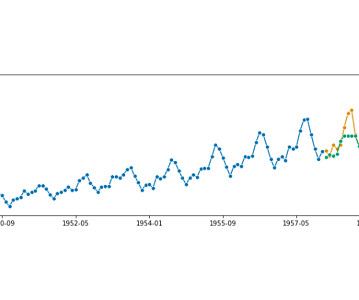
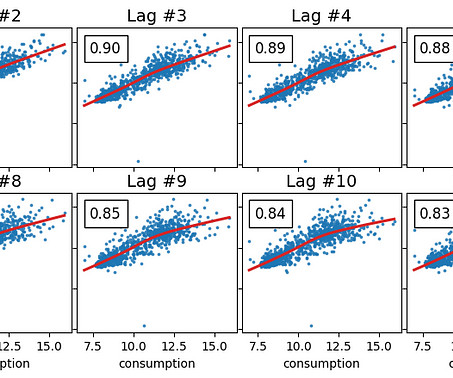
We can plot these with the help of the `plot_pacf` function of the statsmodels Python package: [link] Partial autocorrelation plot for 12 lag features We can clearly see that the first 9 lags possibly contain valuable information since they’re out of the bluish area.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning. He is an industry leader with a passion for innovation.
However, the emergence of the open-source Docker engine by Solomon Hykes in 2013 accelerated the adoption of the technology. These Python virtual environments encapsulate and manage Python dependencies, while Docker encapsulates the project’s dependency stack down to the host OS. Prerequisite Python 3.8 What is Docker?
The repository includes embedding algorithms, such as Word2Vec, GloVe, and Latent Semantic Analysis (LSA), to use with their PIP loss implementation. As such, I’ve adapted and converted the simplest algorithm (LSA) and PIP loss implementations with PyTorch and guided comments for more flexibility. Dosovitskiy, A., Kolesnikov, A.,
VAEs were introduced in 2013 by Diederik et al. It serves as a direct drop-in replacement for the original Fashion-MNIST dataset for benchmarking machine learning algorithms, with the benefit of being more representative of the actual data tasks and challenges. in their paper Auto-Encoding Variational Bayes.
High Demand for Data Scientists: Data Science roles have grown over 250% since 2013, with salaries reaching $153k/year. Job Growth: Data Science roles have grown by 256% since 2013 , with a projected growth rate of 36% between 2023 and 2033. Pythons simplicity and versatility made it the backbone of Dropboxs early development.
In this challenge, solvers submitted an analysis notebook (in R or Python) and a 1-3 page executive summary that highlighted their key findings, summarized their approach, and included selected visualizations from their analyses. Solution format. Guiding questions. There was no one common methodological pattern among the top solutions.
These tools leverage advanced algorithms and methodologies to process large datasets, uncovering valuable insights that can drive strategic decision-making. uses Hadoop to process over 24 petabytes of data daily, enabling them to improve their search algorithms and ad targeting. Use Cases : Yahoo!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content