This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While today’s world is increasingly driven by artificialintelligence (AI) and large language models (LLMs), understanding the magic behind them is crucial for your success. We will start the series by diving into the historical background of embeddings that began from the 2013 Word2Vec paper.
The advancement of artificialintelligence provides new opportunities to automate these processes by leveraging multimedia data, such as voice, body language, and facial expressions. Artificialintelligence techniques, particularly computer vision and machine learning, have led to significant advancements in this field.
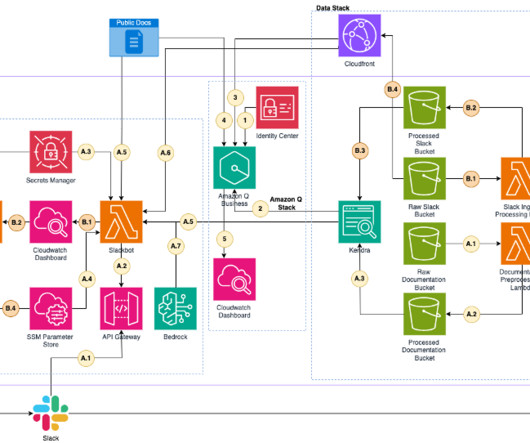
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and data lakes.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
Solution components In this section, we discuss two key components to the solution: the data sources and vector database. Developed by Todd Gamblin at the Lawrence Livermore National Laboratory in 2013, Spack addresses the limitations of traditional package managers in high-performance computing (HPC) environments.
Data pipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a data pipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database. Vector database features built into other services.
Prerequisites For this post, the administrator needs the following prerequisites: A Snowflake user with administrator permission to create a Snowflake virtual warehouse, user, and role, and grant access to this user to create a database. The dataset includes credit card transactions in September 2013 made by European cardholders.
Plotly In the time since it was founded in 2013, Plotly has released a variety of products including Plotly.py, which, along with Plotly.r, Offering an open-source NoSQL graph database, they have also worked with organizations such as eBay, NASA, Lyft, Airbnb, and more.
We create embeddings for each segment and store them in the open-source Chroma vector database via langchain’s interface. We save the database in an Amazon Elastic File System (Amazon EFS) file system for later use. In entered the Big Data space in 2013 and continues to explore that area. text.strip().replace('n',
He highlights innovations in data, infrastructure, and artificialintelligence and machine learning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. Embeddings can be stored in a database and are used to enable streamlined and more accurate searches.
Here are a few reasons why an agent needs tools: Access to external resources: Tools allow an agent to access and retrieve information from external sources, such as databases, APIs, or web scraping. Combining an agent’s decision-making abilities with the functionality provided by tools allows it to perform a wide range of tasks effectively.
In some senses, we are getting closer to a generalisable artificialintelligence; knowledge in deep learning is consolidating into a more paradigmatic approach. Available: [link] (last update, 18/03/2013). Such congruency allows researchers from all disciplines to leverage AI in new and exciting ways. 40] Chung et al.
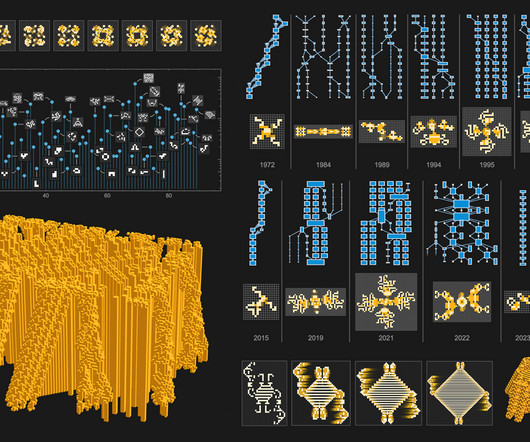
And as a first indication of this, we can plot the number of new Life structures that have been identified each year (or, more specifically, the number of structures deemed significant enough to name, and to record in the LifeWiki database or its predecessors): Theres an immediate impression of several waves of activity.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content