This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
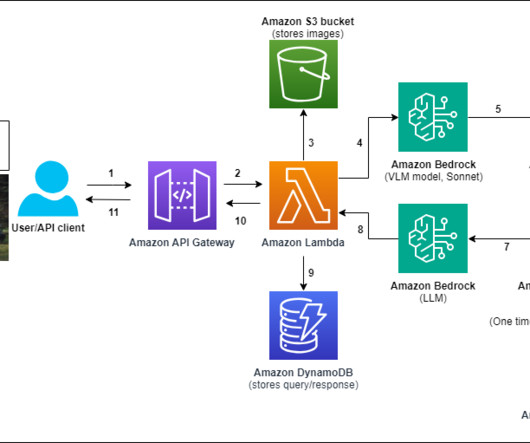
In this post, we show how to create a multimodal chat assistant on Amazon Web Services (AWS) using Amazon Bedrock models, where users can submit images and questions, and text responses will be sourced from a closed set of proprietary documents. For this post, we recommend activating these models in the us-east-1 or us-west-2 AWS Region.
Founded in 2013, Octus, formerly Reorg, is the essential credit intelligence and data provider for the worlds leading buy side firms, investment banks, law firms and advisory firms. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! Now all you need is some guidance on generative AI and machinelearning (ML) sessions to attend at this twelfth edition of re:Invent. are the sessions dedicated to AWS DeepRacer ! And last but not least (and always fun!)
Many organizations are implementing machinelearning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. The need for federated learning in healthcare Healthcare relies heavily on distributed data sources to make accurate predictions and assessments about patient care.
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. You can implement these steps either from the AWS Management Console or using the latest version of the AWS Command Line Interface (AWS CLI). Solutions Architect at AWS. Varun Mehta is a Sr.
Click here to open the AWS console and follow along. Spack is a versatile package manager for supercomputers, Linux, and macOS that revolutionizes scientific software installation by allowing multiple versions, configurations, environments, and compilers to coexist on a single machine.
While it might be easier to start looking at an individual machinelearning (ML) model and the associated risks in isolation, it’s important to consider the details of the specific application of such a model and the corresponding use case as part of a complete AI system. What are the different levels of risk? About the Authors Mia C.
Pattern was founded in 2013 and has expanded to over 1,700 team members in 22 global locations, addressing the growing need for specialized ecommerce expertise. In this post, we share how Pattern uses AWS services to process trillions of data points to deliver actionable insights, optimizing product listings across multiple services.
In this three-part series, we present a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machinelearning (ML) services for a mortgage underwriting use case. Vinnie Saini is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada.
Overall, implementing a modern data architecture and generative AI techniques with AWS is a promising approach for gleaning and disseminating key insights from diverse, expansive data at an enterprise scale. AWS also offers foundation models through Amazon SageMaker JumpStart as Amazon SageMaker endpoints.
Consider the following picture, which is an AWS view of the a16z emerging application stack for large language models (LLMs). This includes native AWS services like Amazon OpenSearch Service and Amazon Aurora. Is your vector database highly available in a single AWS Region? Vector database features built into other services.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. For more information about AWS CDK installation, refer to Getting started with the AWS CDK.
Artificial intelligence and machinelearning are no longer the elements of science fiction; they’re the realities of today. According to Precedence Research , the global market size of machinelearning will grow at a CAGR of a staggering 35% and reach around $771.38 billion by 2032. billion by 2032.
In this pattern, we use Retrieval Augmented Generation using vector embeddings stores, like Amazon Titan Embeddings or Cohere Embed , on Amazon Bedrock from a central data catalog, like AWS Glue Data Catalog , of databases within an organization. In entered the Big Data space in 2013 and continues to explore that area.
Photo by Ian Taylor on Unsplash This article will comprehensively create, deploy, and execute machinelearning application containers using the Docker tool. It will further explain the various containerization terms and the importance of this technology to the machinelearning workflow. What is Docker?
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machinelearning (ML) workflows without writing any code. Choose Create experiment.
Apache Spark Apache Spark is a unified analytics engine for Big Data processing, with built-in modules for streaming, SQL, MachineLearning , and graph processing. Use Cases : Netflix utilizes Spark for real-time analytics and MachineLearning algorithms to enhance user experience through personalized recommendations.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content