This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As competition in AI intensifies, xAI has been ramping up its data center capacity to train more advanced models, and its supercomputer cluster in Memphis, called “Colossus,” is touted as the largest in the world. Musk in February made a $97.4 Reporting by Seher Dareen in Bengaluru; Editing by Pooja Desai and Sandra Maler
Borg’s large-scale cluster management system essentially acts as a central brain for running containerized workloads across its data centers. In 2013, Google introduced Omega, its second-generation container management system. It was also in 2013 that Docker, a key player in Kubernetes history, came into the picture.
In this post, you’ll see an example of performing drift detection on embedding vectors using a clustering technique with large language models (LLMS) deployed from Amazon SageMaker JumpStart. Then we use K-Means to identify a set of cluster centers. A visual representation of the silhouette score can be seen in the following figure.
Containers and Docker Container technology fundamentally changed in 2013 with Docker’s introduction and has continued unabated into this decade, steadily gaining in popularity and user acceptance. Docker containers were originally built around the Docker Engine in 2013 and run according to an application programming interface (API).
IPO in 2013. Tableau had its IPO at the NYSE with the ticker DATA in 2013. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Gestalt properties including clusters are salient on scatters. March 2013), which is our cloud product. Release v1.0
Containers have increased in popularity and adoption ever since the release of Docker in 2013, an open-source platform for building, deploying and managing containerized applications. However, monitoring remains critical, so that organizations have a view into each Kubernetes cluster.
Apache Hadoop Apache Hadoop is an open-source framework that allows for distributed storage and processing of large datasets across clusters of computers using simple programming models. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster. Statistics Kafka handles over 1.1
Each word or sentence is mapped to a high-dimensional vector space, where similar meanings cluster together. exceptions.InsecureRequestWarning) def perform_search(query_text, model_id): """ Perform a search operation using the neural query on the OpenSearch cluster. Figure 3: What Is Semantic Search? disable_warnings(urllib3.exceptions.InsecureRequestWarning)
Solution overview We deploy FedML into multiple EKS clusters integrated with SageMaker for experiment tracking. EKS Blueprints helps compose complete EKS clusters that are fully bootstrapped with the operational software that is needed to deploy and operate workloads. He also holds an MBA from Colorado State University.
IPO in 2013. Tableau had its IPO at the NYSE with the ticker DATA in 2013. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Gestalt properties including clusters are salient on scatters. March 2013), which is our cloud product. Release v1.0
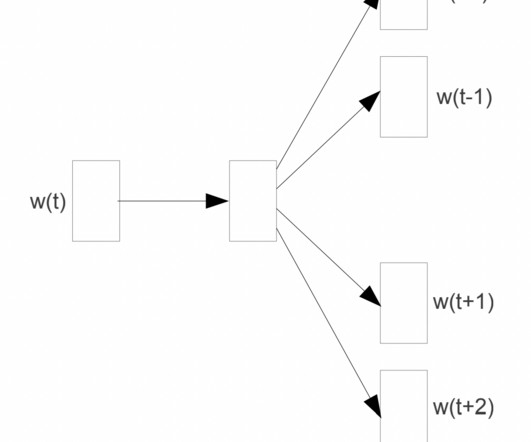
Developed by researchers at Google in 2013 [1], Word2Vec leverages neural networks to learn dense vector representations of words, capturing their semantic and contextual relationships. Understanding Word2Vec Word2Vec is a pioneering natural language processing (NLP) technique that revolutionized the way we represent words in vector space.
For example, rising interest rates and falling equities already in 2013 and again in 2020 and 2022 led to drawdowns of risk parity schemes. In 2023-Q1, we even saw failing banks like SVB simply because of investments in “safe” treasury bonds.
Founded in 2013, Octus, formerly Reorg, is the essential credit intelligence and data provider for the worlds leading buy side firms, investment banks, law firms and advisory firms. Our use of Amazon ECS with Fargate with auto scaling rules and controls gives us elastic scalability for our services during peak usage hours.
Partitioning and clustering features inherent to OTFs allow data to be stored in a manner that enhances query performance. 2013 - Apache Parquet and ORC These columnar storage formats were developed to optimize storage and speed within distributed storage and computing environments.
It was first introduced in 2013 by a team of researchers at Google led by Tomas Mikolov. Image taken from Efficient Estimation of Word Representation in Vector Space Top2Vec Top2Vec is an unsupervised machine-learning model designed for topic modelling and document clustering. To achieve this, Top2Vec utilizes the doc2vec model.
Earthquake data as a geospatial visualization A map view reveals what we’d expect, that the largest clusters of earthquakes occur where tectonic plates meet. Additional investigation reveals that this was the 2013 Russian Okhotsk Sea earthquake. Let’s focus on the major earthquakes between 2010-2011, including the 9.1
Part-of-speech Tagger In 2013, I wrote a blog post describing how to write a good part of speech tagger. The tutorial also recommends the use of Brown cluster features, and case normalization features, as these make the model more robust and domain independent. spaCy’s tagger makes heavy use of these features.
A group of photons initially clustered on neighboring sites will evolve into a superposition of all possible paths each photon might have taken. Among all the possible configuration paths, the only possible scenario that survives is the configuration in which all photons remain clustered together in a bound state.
Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning. Greg has published research in the areas of operating systems, parallel computing, and distributed systems.
VAEs were introduced in 2013 by Diederik et al. By visualizing this space, colored by clothing type, as shown in Figure 9 , we can discern clusters, patterns, and potential correlations between different attributes. Similar class labels tend to form clusters, as observed with the Convolutional Autoencoder.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., 2013; Goodfellow et al., 2012; Otsu, 1979; Long et al., Challenges in representation learning: A report on three machine learning contests. Neural Networks, 64, 59–63.
For the similarity metric, I’ve been using a distance function taken from Chen (2013) , which he terms Cauchy Similarity : def ChenCauchy(length): '''Create a trainable similarity function, that will return the similarity and a callback to compute the backward pass given the gradient.
You can find it in the turning of the seasons, in the way sand trails along a ridge, in the branch clusters of the creosote bush or the pattern of its leaves. Word2vec is a method to efficiently create word embeddings and has been around since 2013. Yet, it is possible to see peril in the finding of ultimate perfection.
Nagle’s brain implant, developed by the research consortium BrainGate , contained a “Utah” array, a cluster of 100 spiky electrodes that is surgically embedded into the brain. In 2006, Matthew Nagle, a man with spinal cord paralysis, received a brain implant that allowed him to control a computer cursor.
We tried several methods to reconstruct its original appearance: In 2013 we commissioned a picture by Greg O’Leary , a professional portrait artist. In 2012, with the permission of the police, Janette used a magnifying glass to find where several hairs came together in a cluster.
Well, actually, you’ll still have to wonder because right now it’s just k-mean cluster colour, but in the future you won’t). Within both embedding pages, the user can choose the number of embeddings to show, how many k-mean clusters to split these into, as well as which embedding type to show. References Harris, Z. Mikolov, T.,
Solvers submitted a wide range of methodologies to this end, including using open-source and third party LLMs (GPT, LLaMA), clustering (DBSCAN, K-Means), dimensionality reduction (PCA), topic modeling (LDA, BERT), sentence transformers, semantic search, named entity recognition, and more. and DistilBERT.
This month I used a new embedding model (Nomic), switch out UMAP for PaCMAP, and added automatic cluster labelling. The clustering and dimensionality reduction aren't quite as stable as I'd like, but most seeds give decent results now. Been working on it since 2013.
According to associates, his decision was directly influenced by mapping UFO sighting clusters and abduction reports across the United States. 2011-2013 Expands operations to include multiple locations across the Southwest. 2010 Publishes “Blank Space,” a cryptic book combining photography, philosophy, and coded messages.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content