This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, you’ll see an example of performing drift detection on embedding vectors using a clustering technique with large language models (LLMS) deployed from Amazon SageMaker JumpStart. Then we use K-Means to identify a set of cluster centers. A visual representation of the silhouette score can be seen in the following figure.
Many organizations are implementing machinelearning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. Because this data is across organizations, we use federated learning to collate the findings. He entered the big data space in 2013 and continues to explore that area.
Founded in 2013, Octus, formerly Reorg, is the essential credit intelligence and data provider for the worlds leading buy side firms, investment banks, law firms and advisory firms. He specializes in generative AI, machinelearning, and system design.
IPO in 2013. Tableau had its IPO at the NYSE with the ticker DATA in 2013. Even modern machinelearning applications should use visual encoding to explain data to people. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Release v1.0 Query innovation.
Containers and Docker Container technology fundamentally changed in 2013 with Docker’s introduction and has continued unabated into this decade, steadily gaining in popularity and user acceptance. Docker containers were originally built around the Docker Engine in 2013 and run according to an application programming interface (API).
For example, rising interest rates and falling equities already in 2013 and again in 2020 and 2022 led to drawdowns of risk parity schemes. His interests are financial markets, asset management, and machinelearning applications.
Iris was designed to use machinelearning (ML) algorithms to predict the next steps in building a data pipeline. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machinelearning.
IPO in 2013. Tableau had its IPO at the NYSE with the ticker DATA in 2013. Even modern machinelearning applications should use visual encoding to explain data to people. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Release v1.0 Query innovation.
It was first introduced in 2013 by a team of researchers at Google led by Tomas Mikolov. Word2Vec is a shallow neural network that learns to predict the probability of a word given its context (CBOW) or the context given a word (skip-gram). For this, Top2Vec utilizes a manifold learning technique called UMAP.
Developed by researchers at Google in 2013 [1], Word2Vec leverages neural networks to learn dense vector representations of words, capturing their semantic and contextual relationships. At its core, Word2Vec is based on the distributional hypothesis, which states that words occurring in similar contexts tend to have similar meanings.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machinelearning (Arbeláez et al., an image) with the intention of causing a machinelearning model to misclassify it (Goodfellow et al., 2013; Goodfellow et al.,
VAEs were introduced in 2013 by Diederik et al. They extended the idea of autoencoders to learn useful data distributions. It serves as a direct drop-in replacement for the original Fashion-MNIST dataset for benchmarking machinelearning algorithms, with the benefit of being more representative of the actual data tasks and challenges.
You can find it in the turning of the seasons, in the way sand trails along a ridge, in the branch clusters of the creosote bush or the pattern of its leaves. In such perfection, all things move toward death.” ~ Dune (1965) I find the concept of embeddings to be one of the most fascinating ideas in machinelearning.
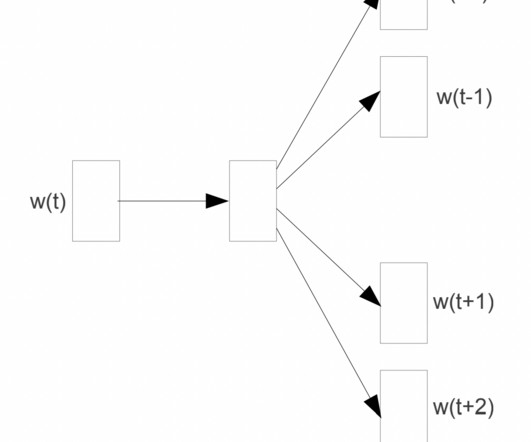
For instance, consider the sentence “ I like machinelearning ” and a context window of size 1. Then, the words which give context, or appear in the context window around the word “ machine” , are “ like ” and “ learning ” (the window is considered both on the left and on the right). References Harris, Z. Mikolov, T.,
In the Unsupervised Wisdom Challenge , participants were tasked with identifying novel, effective methods of using unsupervised machinelearning to extract insights about older adult falls from narrative medical record data. Solution format. However, it wasn't the use of sophisticated tools alone that made for strong submissions.
Apache Hadoop Apache Hadoop is an open-source framework that allows for distributed storage and processing of large datasets across clusters of computers using simple programming models. It is designed to scale up from a single server to thousands of machines. Durability: Messages are stored on disk and replicated within the cluster.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content