This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
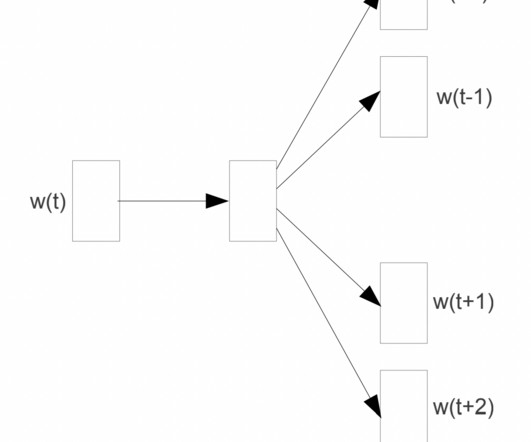
It was first introduced in 2013 by a team of researchers at Google led by Tomas Mikolov. Image taken from Efficient Estimation of Word Representation in Vector Space Top2Vec Top2Vec is an unsupervised machine-learning model designed for topic modelling and document clustering. To achieve this, Top2Vec utilizes the doc2vec model.
Some might also wonder how I get Python code to run so fast. This makes it easy to achieve the performance of native C code, but allows the use of Python language features, via the Python C API. The Python unicode library was particularly useful to me. Here is what the outer-loop would look like in Python.
VAEs were introduced in 2013 by Diederik et al. By visualizing this space, colored by clothing type, as shown in Figure 9 , we can discern clusters, patterns, and potential correlations between different attributes. Similar class labels tend to form clusters, as observed with the Convolutional Autoencoder.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., 2013; Goodfellow et al., 2012; Otsu, 1979; Long et al., Challenges in representation learning: A report on three machine learning contests. Neural Networks, 64, 59–63.
In this challenge, solvers submitted an analysis notebook (in R or Python) and a 1-3 page executive summary that highlighted their key findings, summarized their approach, and included selected visualizations from their analyses. Solution format. Guiding questions.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning. He currently is working on Generative AI for data integration.
Apache Hadoop Apache Hadoop is an open-source framework that allows for distributed storage and processing of large datasets across clusters of computers using simple programming models. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster. Statistics Kafka handles over 1.1
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content