This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To get you started, DataScience Dojo and Weaviate have teamed up to bring you an exciting webinar series: Master Vector Embeddings with Weaviate. We have carefully curated the series to empower AI enthusiasts, data scientists, and industry professionals with a deep understanding of vector embeddings.
These organizations are shaping the future of the AI and datascience industries with their innovative products and services. Making Data Observable Bigeye The quality of the data powering your machine learning algorithms should not be a mystery. Check them out below.
Despite the furore that erupted after Cambridge Analytica, the dirty data problem hasn’t gone away: major breaches are commonplace, with a report by Apple last year indicating that the total number of data breaches tripled between 2013 and 2022. In the past two years alone, 2.6
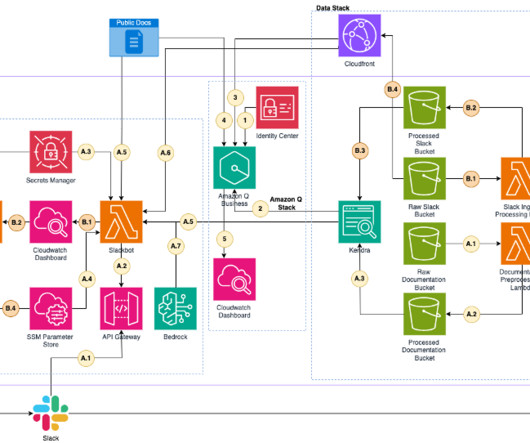
Solution components In this section, we discuss two key components to the solution: the data sources and vector database. Data sources We use Spack documentation RST (ReStructured Text) files uploaded in an Amazon Simple Storage Service (Amazon S3) bucket. Their raw files can be served in a CloudFront distribution.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
How Does Big Data Architecture Fit with a Translation Company? Big data architecture lays out the technical specifics of processing and analyzing larger amounts of data than traditional database systems can handle. Further, big data itself incorporates working with growing amounts of data these days.
We create embeddings for each segment and store them in the open-source Chroma vector database via langchain’s interface. We save the database in an Amazon Elastic File System (Amazon EFS) file system for later use. In entered the Big Data space in 2013 and continues to explore that area. text.strip().replace('n',
In this pattern, the recipe text is converted into embedding vectors using an embedding model, and stored in a vector database. Incoming questions are converted to embeddings, and then the vector database runs a similarity search to find related content. The question and the reference data then go into the prompt for the LLM.
Here are a few reasons why an agent needs tools: Access to external resources: Tools allow an agent to access and retrieve information from external sources, such as databases, APIs, or web scraping. This enables the agent to gather relevant data and use it for decision-making.
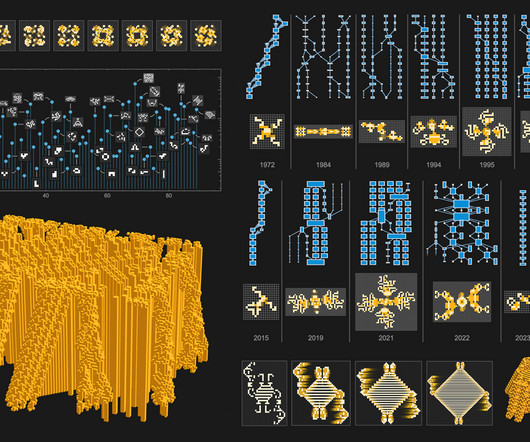
And as a first indication of this, we can plot the number of new Life structures that have been identified each year (or, more specifically, the number of structures deemed significant enough to name, and to record in the LifeWiki database or its predecessors): Theres an immediate impression of several waves of activity.
Artem has versatile experience in working with real-life data from different domains and was involved in several datascience projects at the World Bank and the University of Oxford. He actively participates in datascience competitions, consistently achieving top places. What motivated you to participate? :
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content