This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We will start the series by diving into the historical background of embeddings that began from the 2013 Word2Vec paper. Here’s a guide to choosing the right vector embedding model Importance of Vector Databases in Vector Search Vector databases are the backbone of efficient and scalable vector search.
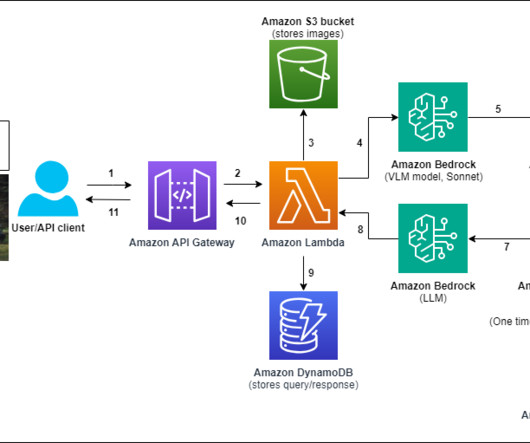
Solution overview For our custom multimodal chat assistant, we start by creating a vector database of relevant text documents that will be used to answer user queries. The 2013 Jeep Grand Cherokee SRT8 listing is most relevant, with an asking price of $17,000 despite significant body damage from an accident. turbocharged engine.
Despite the furore that erupted after Cambridge Analytica, the dirty data problem hasn’t gone away: major breaches are commonplace, with a report by Apple last year indicating that the total number of data breaches tripled between 2013 and 2022. In the past two years alone, 2.6
From that story: “Among those who grabbed a copy of the database was Antti Kurittu , a team lead at Nixu Corporation and a former criminal investigator. There were also other projects and databases.” According to the French news site actu.fr , Kivimäki was arrested around 7 a.m.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and data lakes.
Decentralized finance, or DeFi, emerged as a part of the crypto industry in 2013. The post A Checklist to Manage Your Database if You’re into DeFi appeared first on DATAVERSITY. As the name suggests, DeFi refers to peer-to-peer applications that allow crypto trading, loans among other services to take place digitally.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
Solution components In this section, we discuss two key components to the solution: the data sources and vector database. Developed by Todd Gamblin at the Lawrence Livermore National Laboratory in 2013, Spack addresses the limitations of traditional package managers in high-performance computing (HPC) environments.
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
Data pipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a data pipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database. Vector database features built into other services.
People who used Google between October 2006 and September 2013 to do searches and click on search results may be eligible to earn a portion of the $23 million settlement Google has agreed to pay. You can get the Google class action lawsuit claim since it’s claimed that Google mistreated your data and privacy.
To do this, the text input is transformed into a structured representation, and from this representation, a SQL query that can be used to access a database is created. The primary goal of Text2SQL is to make querying databases more accessible to non-technical users, who can provide their queries in natural language. gymnast_id = t2.
IPO in 2013. Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first EOM contract with the database company Hyperion—that’s when I was hired. Release v1.0
Founded in 2013, Octus, formerly Reorg, is the essential credit intelligence and data provider for the worlds leading buy side firms, investment banks, law firms and advisory firms. The integration of text-to-SQL will enable users to query structured databases using natural language, simplifying data access.
Big data architecture lays out the technical specifics of processing and analyzing larger amounts of data than traditional database systems can handle. Even by 2013, 90% of the data in the world had been generated within the previous two years. How Does Big Data Architecture Fit with a Translation Company? That’s just staggering.
The following question requires complex industry knowledge-based analysis of data from multiple columns in the ETF database. In entered the Big Data space in 2013 and continues to explore that area. Use case examples Let’s look at a few sample prompts with generated analysis. He also holds an MBA from Colorado State University.
One of my pet peeves is rooted in Sean Parents 2013 talk at GoingNative, Seasoning C++ where he advocated for no raw loops. Otherwise, if you write code where you also do some network calls or read from the database or from the filesystem, these differences are negligible and you should go with the version that you find the most readable.
2013 - Apache Parquet and ORC These columnar storage formats were developed to optimize storage and speed within distributed storage and computing environments. With the introduction of SQL capabilities, they are accessible to users who are accustomed to querying relational databases What is an External Table?
Fast Company wrote about this back in 2013 when they said that Big Data is Rewriting Hollywood Scripts. There is a large database that can help you find what you are looking for. A growing number of screenwriters are discovering the wonders of big data. It’s always about how you sell your remarkable project to them.
In Outlook 2013 and earlier versions, IMAP accounts also used.pst file. In addition, you can easily export OST data directly to Office 365 and any live database of Exchange Server. What’s the difference between PST and OST? PST file is used by legacy messaging protocols – POP, IMAP, or older mail servers.
Prerequisites For this post, the administrator needs the following prerequisites: A Snowflake user with administrator permission to create a Snowflake virtual warehouse, user, and role, and grant access to this user to create a database. The dataset includes credit card transactions in September 2013 made by European cardholders.
IPO in 2013. Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first OEM contract with the database company Hyperion—that’s when I was hired. Release v1.0
Netezza Performance Server (NPS) has recently added the ability to access Parquet files by defining a Parquet file as an external table in the database. All SQL and Python code is executed against the NPS database using Jupyter notebooks, which capture query output and graphing of results during the analysis phase of the demonstration.
In 2020, we added the ability to write to external databases so you can use clean data anywhere. We’ll never dictate your technology stack, database preferences, or analytics strategy, so you can rely on Tableau no matter what data you have, no matter where it is. . And we extended the Prep connectivity options.
According to National Day Calendar, this idea gained traction in May 2013, when Intel Security selected the first Thursday each May as World Password […]. World Password Day was born back in 2005 when security researcher Mark Burnett suggested that everyone embrace a specific day in which they update their digital passwords.
Plotly In the time since it was founded in 2013, Plotly has released a variety of products including Plotly.py, which, along with Plotly.r, Offering an open-source NoSQL graph database, they have also worked with organizations such as eBay, NASA, Lyft, Airbnb, and more.
We create embeddings for each segment and store them in the open-source Chroma vector database via langchain’s interface. We save the database in an Amazon Elastic File System (Amazon EFS) file system for later use. In entered the Big Data space in 2013 and continues to explore that area. text.strip().replace('n',
Some commonly used datasets include CK+ (Extended Cohn-Kanade dataset), MMI (Multimedia Understanding Group database), AffectNet, and FER2013 (Facial Expression Recognition 2013). Datasets: Several datasets have been developed and used by the research community to train and evaluate facial expression detection models.
Ryan Stryker Senior Technical Architect, Tableau Kathleen Goepferd September 25, 2013 - 11:56pm January 20, 2023 The modern Tableau Server offers Creators a Desktop-like experience for establishing database connections and drawing extracts.
Ryan Stryker Senior Technical Architect, Tableau Kathleen Goepferd September 25, 2013 - 11:56pm January 20, 2023 The modern Tableau Server offers Creators a Desktop-like experience for establishing database connections and drawing extracts.
Every time someone goes shopping or buys a service (whether online or offline), their personal data is entered into a computer database. Target experienced one of the largest attacks in the history of retail America on or before Black Friday of 2013. Metadata is basically a trail of data that is spread out across a network.
USE ROLE admin; GRANT USAGE ON DATABASE admin_db TO ROLE analyst; GRANT USAGE ON SCHEMA admin_schema TO ROLE analyst; GRANT CREATE SNOWFLAKE.ML.FORECAST ON SCHEMA admin_db.admin_schema TO ROLE analyst; Next, let’s create the table to house the historical data in our Walmart Demand Forecasting.
The product collected an impressive amount of metadata, from the user interface to the database structure. It wouldn’t be until 2013 that the topic of data lineage would surface again – this time while working on a data warehouse project. It then translated all that metadata into an image resembling a spider’s web.
In this pattern, the recipe text is converted into embedding vectors using an embedding model, and stored in a vector database. Incoming questions are converted to embeddings, and then the vector database runs a similarity search to find related content. In entered the Big Data space in 2013 and continues to explore that area.
Embeddings can be stored in a database and are used to enable streamlined and more accurate searches. To overcome this limitation, you can supplement prompts with up-to-date information using embeddings stored in vector databases, a process known as Retrieval Augmented Generation (RAG).
In 2020, we added the ability to write to external databases so you can use clean data anywhere. We’ll never dictate your technology stack, database preferences, or analytics strategy, so you can rely on Tableau no matter what data you have, no matter where it is. . And we extended the Prep connectivity options.
October 5, 2013. ImageNet: A Large-Scale Hierarchical Image Database.” December 14, 2015. link] [2] Donahue, Jeff, Yangqing Jia, Oriol Vinyals, Judy Hoffman, Ning Zhang, Eric Tzeng, and Trevor Darrell. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition.” link] [3] He, Kaiming, Ross Girshick, and Piotr Dollár.
FREE: The ultimate guide to graph visualization Proven strategies for building successful graph visualization applications GET YOUR FREE GUIDE The earthquakes data source The data I used is from the USGS’s National Earthquake Information Center (NEIC), whose extensive databases of seismic information are freely available.
Here are a few reasons why an agent needs tools: Access to external resources: Tools allow an agent to access and retrieve information from external sources, such as databases, APIs, or web scraping. Combining an agent’s decision-making abilities with the functionality provided by tools allows it to perform a wide range of tasks effectively.
A somewhat-recent technique, taking inspiration from earlier work but popularised by Alex Graves’s in 2013/2014, it has grown in use partially from his memory-related work: the now-famous sequence generation paper [36] along with his work on neural turing machines. [37] Available: [link] (last update, 18/03/2013). 40] Chung et al.
We tried several methods to reconstruct its original appearance: In 2013 we commissioned a picture by Greg O’Leary , a professional portrait artist. However, to identify Somerton Man using DNA databases, we needed to go to autosomal DNA—the kind that is inherited from both parents.
Maternal mortality rates in the United States jumped over 25% between 2000 and 2013. Big data is also being fed into databases from social media, blood tests, doctor visits, email, forums and a variety of other mediums. Understaffed hospitals and medical errors are causing most of the deaths.
Aaron created a system to download public domain court documents from PACER, a government database that charged fees for accessing what he believed should be freely available public information. Aaron helped develop RSS web feeds, co-founded Reddit, and worked with Creative Commons to create flexible copyright licenses for the common good.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content