This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We will start the series by diving into the historical background of embeddings that began from the 2013 Word2Vec paper. Here’s a guide to choosing the right vector embedding model Importance of Vector Databases in Vector Search Vector databases are the backbone of efficient and scalable vector search.
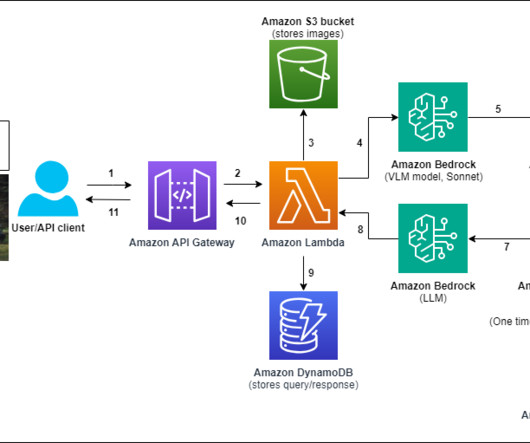
Solution overview For our custom multimodal chat assistant, we start by creating a vector database of relevant text documents that will be used to answer user queries. This script can be acquired directly from Amazon S3 using aws s3 cp s3://aws-blogs-artifacts-public/artifacts/ML-16363/deploy.sh. us-east-1 or bash deploy.sh
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. In addition to several exciting announcements during keynotes, most of the sessions in our track will feature generative AI in one form or another, so we can truly call our track “Generative AI and ML.”
A generative AI foundation can provide primitives such as models, vector databases, and guardrails as a service and higher-level services for defining AI workflows, agents and multi-agents, tools, and also a catalog to encourage reuse. Considerations here are choice of vector database, optimizing indexing pipelines, and retrieval strategies.
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and data lakes.
IPO in 2013. Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first EOM contract with the database company Hyperion—that’s when I was hired. Release v1.0
Solution components In this section, we discuss two key components to the solution: the data sources and vector database. Developed by Todd Gamblin at the Lawrence Livermore National Laboratory in 2013, Spack addresses the limitations of traditional package managers in high-performance computing (HPC) environments.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
Data pipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a data pipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database. Vector database features built into other services.
To do this, the text input is transformed into a structured representation, and from this representation, a SQL query that can be used to access a database is created. The primary goal of Text2SQL is to make querying databases more accessible to non-technical users, who can provide their queries in natural language. gymnast_id = t2.
The brand-new Forecasting tool created on Snowflake Data Cloud Cortex ML allows you to do just that. What is Cortex ML, and Why Does it Matter? Cortex ML is Snowflake’s newest feature, added to enhance the ease of use and low-code functionality of your business’s machine learning needs.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
The following question requires complex industry knowledge-based analysis of data from multiple columns in the ETF database. In entered the Big Data space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences including Strata and GlueCon.
Founded in 2013, Octus, formerly Reorg, is the essential credit intelligence and data provider for the worlds leading buy side firms, investment banks, law firms and advisory firms. The integration of text-to-SQL will enable users to query structured databases using natural language, simplifying data access.
IPO in 2013. Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first OEM contract with the database company Hyperion—that’s when I was hired. Release v1.0
To deliver on their commitment to enhancing human ingenuity, SAS’s ML toolkit focuses on automation and more to provide smarter decision-making. Plotly In the time since it was founded in 2013, Plotly has released a variety of products including Plotly.py, which, along with Plotly.r,
We create embeddings for each segment and store them in the open-source Chroma vector database via langchain’s interface. We save the database in an Amazon Elastic File System (Amazon EFS) file system for later use. In entered the Big Data space in 2013 and continues to explore that area. text.strip().replace('n',
Text-to-Vector Conversion (Sentence Transformer Model) Inside OpenSearch, the neural search module passes the query text to a pre-trained Sentence Transformer model (from Hugging Face or another ML framework). The model converts the query text into a dense vector representation (embedding).
In this pattern, the recipe text is converted into embedding vectors using an embedding model, and stored in a vector database. Incoming questions are converted to embeddings, and then the vector database runs a similarity search to find related content. In entered the Big Data space in 2013 and continues to explore that area.
Machine Learning Integration : Built-in ML capabilities streamline model development and deployment. Real-Time Data Analysis: Connects seamlessly with various databases for live analysis. Statistics: Tableau has been recognized as a leader in the Gartner Magic Quadrant for Analytics and Business Intelligence Platforms since 2013.
ML practitioners, believing they had to match the sheer size of ImageNet, refrained from pre-training with much smaller available medical image datasets, let alone developing new ones. October 5, 2013. ImageNet: A Large-Scale Hierarchical Image Database.” December 14, 2015. link] [3] He, Kaiming, Ross Girshick, and Piotr Dollár.
Here are a few reasons why an agent needs tools: Access to external resources: Tools allow an agent to access and retrieve information from external sources, such as databases, APIs, or web scraping. Combining an agent’s decision-making abilities with the functionality provided by tools allows it to perform a wide range of tasks effectively.
A somewhat-recent technique, taking inspiration from earlier work but popularised by Alex Graves’s in 2013/2014, it has grown in use partially from his memory-related work: the now-famous sequence generation paper [36] along with his work on neural turing machines. [37] Available: [link] (last update, 18/03/2013). 40] Chung et al.
Summary of approach : Using a downsampling method with ChatGPT and ML techniques, we obtained a full NEISS dataset across all accidents and age groups from 2013-2022 with six new variables: fall/not fall, prior activity, cause, body position, home location, and facility.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content