This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (Natural Language Processing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. NLP algorithms help computers understand, interpret, and generate natural language.
Overhyped or not, investments in AI drug discovery jumped from $450 million in 2014 to a whopping $58 billion in 2021. AI began back in the 1950s as a simple series of “if, then rules” and made its way into healthcare two decades later after more complex algorithms were developed. AI drug discovery is exploding.
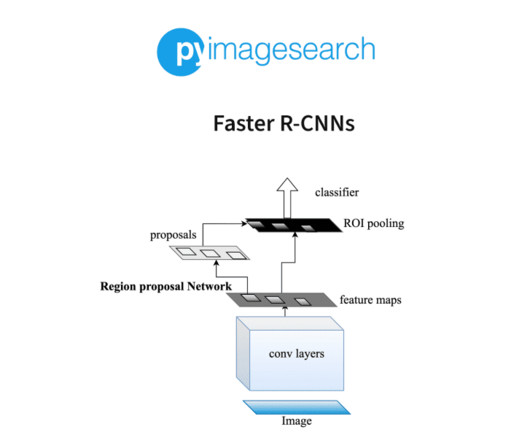
One of the most popular deep learning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al. Since then, the R-CNN algorithm has gone through numerous iterations, improving the algorithm with each new publication and outperforming traditional object detection algorithms (e.g.,
Uysal and Gunal, 2014). Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. Figure 11 Model Architecture The algorithms and models used for the first three classifiers are essentially the same.
Crafting a dataset The number of papers added to ArXiv per month since 2014. As a starting point for our lofty goal, we used the arxiv-sanity code base (created by Andrej Karpathy) to collect ~50,000 papers from the ArXiv API released from 2014 onwards and which were in the fields of cs. Every month except January.
This is embedding/vector/vector embedding for this article. Use algorithm to determine closeness/similarity of points. Overview Vector Embedding 101: The Key to Semantic Search Vector indexing: when you have millions or more vectors, searching through them would be very tedious without indexing.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content