
Deep Learning for NLP: Word2Vec, Doc2Vec, and Top2Vec Demystified
Mlearning.ai
APRIL 1, 2023
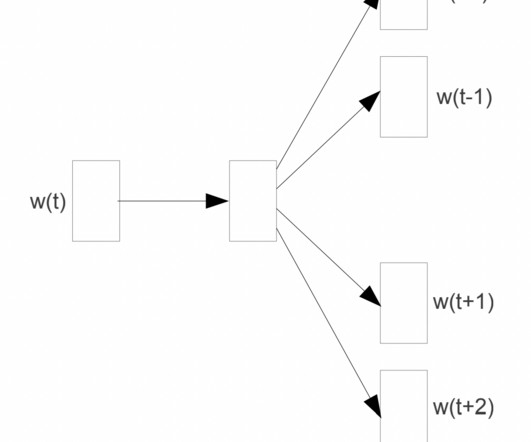
Doc2Vec Doc2Vec, also known as Paragraph Vector, is an extension of Word2Vec that learns vector representations of documents rather than words. Doc2Vec was introduced in 2014 by a team of researchers led by Tomas Mikolov. Doc2Vec learns vector representations of documents by combining the word vectors with a document-level vector.

















Let's personalize your content