This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
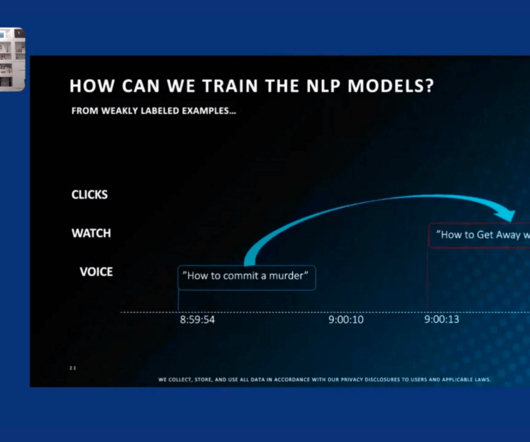
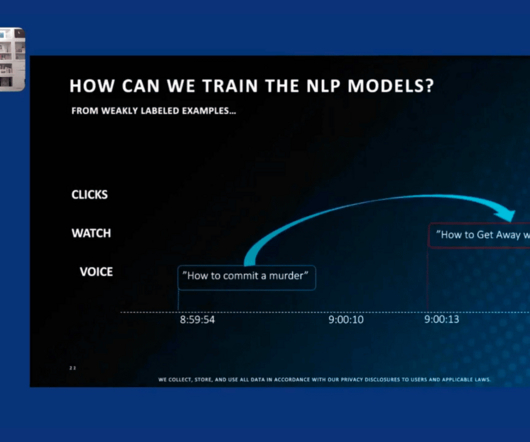
The biggest breakthroughs in machine learning have only emerged over the last five years, as new advances in Hadoop and other big data technology make artificial intelligence algorithms more practical. Google Photos was first launched in 2015. Google Photos used complex machine learning algorithms to solve this challenge.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
According to a 2015 whitepaper published in Science Direct , big data is one of the most disruptive technologies influencing the field of academia. A selection of information sources, data acquisition procedures, information processing algorithms. Organization of data collection in a single database. Data collection.
Here are some of the key features of open source BI software: Data integration: Open source BI software can pull data from various sources, such as databases, spreadsheets, and cloud services, and integrate it into a single location for analysis. This ensures that all data is available for analysis in one central location.
This dataset comprises a multi-center critical care database collected from over 200 hospitals, which makes it ideal to test our FL experiments. We used the eICU Collaborative Research Database , a multi-center intensive care unit (ICU) database, comprising 200,859 patient unit encounters for 139,367 unique patients.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. Try the new interactive demo to explore similarities and compare them between 2015 and 2019 sense2vec (Trask et. Interestingly, “to ghost” wasn’t very common in 2015.
To make things easy, these three inputs depend solely on the model name, version (for a list of the available models, see Built-in Algorithms with pre-trained Model Table ), and the type of instance you want to train on. learning_rate – Controls the step size or learning rate of the optimization algorithm during training.
billion in 2015 and reached around $26.50 Here are steps you can follow to pursue a career as a BI Developer: Acquire a solid foundation in data and analytics: Start by building a strong understanding of data concepts, relational databases, SQL (Structured Query Language), and data modeling. billion in 2021.
People don’t even need the in-depth knowledge of the various machine learning algorithms as it contains pre-built libraries. PyTorch PyTorch is a popular, open-source, and lightweight machine learning and deep learning framework built on the Lua-based scientific computing framework for machine learning and deep learning algorithms.
Sometimes it’s a story of creating a superalgorithm that encapsulates decades of algorithmic development. And in a similar vein, we can expect LLMs to be useful in making connections to external databases, functions, etc. In addition, a new algorithm in Version 14.0 had 554 built-in functions; in Version 14.0 there are 6602.
GraphViz [Graphviz] has important applications in networking, bioinformatics, software engineering, database and web design, machine learning, and in visual interfaces for other technical domains. cdnjs.com History: Made available and maintained by mdaines at slowscan.net since 2015. A hack to put GraphViz on the web.
To make things easy, these three inputs depend solely on the model name, version (for a list of the available models, see Built-in Algorithms with pre-trained Model Table ), and the type of instance you want to train on. learning_rate – Controls the step size or learning rate of the optimization algorithm during training.
C++ also provides direct access to low-level features like pointers and bitwise operations, which can improve the efficiency of algorithms and data structures. It was developed by Google and released in 2015. This is critical for computer vision jobs that need real-time processing and precision.
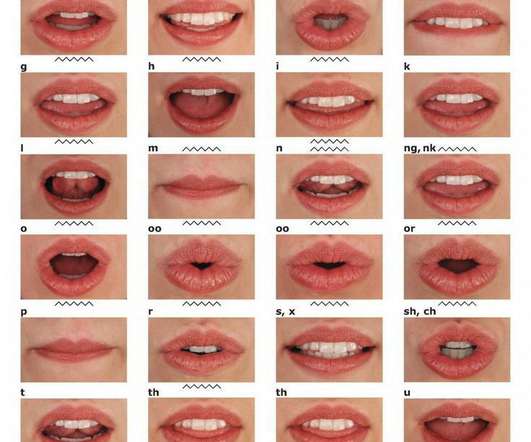
17] “ LipNet ” introduces the first approach for an end-to-end lip reading algorithm at sentence level. 27] LipNet also makes use of an additional algorithm typically used in speech recognition systems — a Connectionist Temporal Classification (CTC) output. Thus the algorithm is alignment-free. Vive Differentiable Programming!
Here is a brief description of the algorithm: OpenAI collected prompts submitted by the users to the earlier versions of the model. This not only makes the system extremely biased by also makes it more of an intelligent search algorithm than a truly intelligent system.
For example, building algorithms that run on our cameras and detect if somebody is coming home, or if a package gets delivered for you. The voice remote was launched for Comcast in 2015. We also have a team focused on the Digital Home and the applications of AI inside of it. And finally, also, AI/ML innovation and educational efforts.
For example, building algorithms that run on our cameras and detect if somebody is coming home, or if a package gets delivered for you. The voice remote was launched for Comcast in 2015. We also have a team focused on the Digital Home and the applications of AI inside of it. And finally, also, AI/ML innovation and educational efforts.
But I want to at least give our perspective on what motivated us back in 2015 to start talking about this and to start studying it back at Stanford, where the Snorkel team started: this idea of a shift from model-centric to data-centric AI development. So we’re going to be hearing about lots of topics.
But I want to at least give our perspective on what motivated us back in 2015 to start talking about this and to start studying it back at Stanford, where the Snorkel team started: this idea of a shift from model-centric to data-centric AI development. So we’re going to be hearing about lots of topics.
Advance algorithms and analytic approaches for early prediction of AD/ADRD, with an emphasis on explainability of predictions. Top solvers from Phase 2 demonstrate algorithmic approaches on diverse datasets and share their results at an innovation event. Phase 2 [Build IT!] Phase 3 [Put IT All Together!]
Algorithms are important and require expert knowledge to develop and refine, but they would be useless without data. These datasets, essentially large collections of related information, act as the training field for machine learning algorithms. This involves feeding the images and their corresponding labels into an algorithm (e.g.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content