This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional learning approaches Traditional machine learning predominantly relied on supervised learning, a process where models were trained using labeled datasets. In this approach, the algorithm learns patterns and relationships between input features and corresponding output labels.
Kingma is best known for co-developing several groundbreaking techniques in AI, including the Adam optimizer , a widely-used optimization algorithm in deep learning, and Variational Autoencoders (VAE) , a type of generative model that enables unsupervised learning and has applications in image generation and other AI tasks.
It involves using machine learning algorithms to generate new data based on existing data. Generative AI is a subset of artificial intelligence (AI) that involves using algorithms to create new data. Generative AI works by training algorithms on large datasets, which the algorithm can then use to generate new data.
Traditional learning approaches Traditional machine learning predominantly relied on supervised learning, a process where models were trained using labeled datasets. In this approach, the algorithm learns patterns and relationships between input features and corresponding output labels.
In the first part of the series, we talked about how Transformer ended the sequence-to-sequence modeling era of NaturalLanguageProcessing and understanding. In 2015, Andrew M. So, the authors have used a two-stage process, following what we do as humans.
Naturallanguageprocessing (NLP) is the field in machine learning (ML) concerned with giving computers the ability to understand text and spoken words in the same way as human beings can. For this solution, we use the 2015 New Year’s Resolutions dataset to classify resolutions.
Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. From 2015–2018, he worked as a program director at the US NSF in charge of its big data program. He founded StylingAI Inc.,
The most common techniques used for extractive summarization are term frequency-inverse document frequency (TF-IDF), sentence scoring, text rank algorithm, and supervised machine learning (ML). Use the evaluation algorithm with either built-in or custom datasets to evaluate your LLM model.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., Understanding the robustness of image segmentation algorithms to adversarial attacks is critical for ensuring their reliability and security in practical applications.
This retrieval can happen using different algorithms. Her research interests lie in NaturalLanguageProcessing, AI4Code and generative AI. His research interests lie in the area of AI4Code and NaturalLanguageProcessing. He received his PhD from University of Maryland, College Park in 2010.
His research focuses on applying naturallanguageprocessing techniques to extract information from unstructured clinical and medical texts, especially in low-resource settings. I love participating in various competitions involving deep learning, especially tasks involving naturallanguageprocessing or LLMs.
TensorFlow The Google Brain team created the open-source deep learning framework TensorFlow, which was made available in 2015. TensorFlow implements a wide range of deep learning and machine learning algorithms and is well-known for its adaptability and extensive ecosystem. In 2011, H2O.ai
This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy. It is based on GPT and uses machine learning algorithms to generate code suggestions as developers write.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. Try the new interactive demo to explore similarities and compare them between 2015 and 2019 sense2vec (Trask et. Interestingly, “to ghost” wasn’t very common in 2015.
Recent Intersections Between Computer Vision and NaturalLanguageProcessing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and NaturalLanguageProcessing (NLP). Source : Johnson et al. using Faster-RCNN[ 82 ].
In industry, it powers applications in computer vision, naturallanguageprocessing, and reinforcement learning. This allows users to change the network architecture on-the-fly, which is particularly useful for tasks that require variable input sizes, such as naturallanguageprocessing and reinforcement learning.
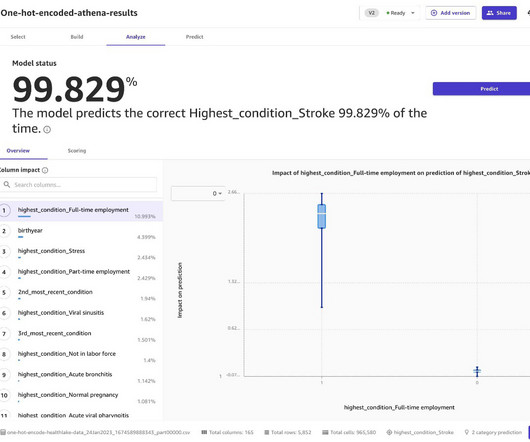
Use naturallanguageprocessing (NLP) in Amazon HealthLake to extract non-sensitive data from unstructured blobs. One of the challenges of working with categorical data is that it is not as amenable to being used in many machine learning algorithms. Perform one-hot encoding with Amazon SageMaker Data Wrangler.
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects. It advances the scalability of ML in real-world applications by using algorithms to improve model performance and reproducibility. What is MLOps?
For example, they can scan test papers with the help of naturallanguageprocessing (NLP) algorithms to detect correct answers and grade them accordingly. Further, by analyzing grades, the software can analyze where individual students are lacking and how they can improve the learning process.
SyntaxNet provides an important module in a naturallanguageprocessing (NLP) pipeline such as spaCy. If you’ve been using the neural network model in Stanford CoreNLP , you’re using an algorithm that’s almost identical in design, but not in detail. It already did. But I definitely think there’s still much more to come.
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
By late 2015 I had the machine learning, hash table, outer parsing loop, and most of the feature extraction as nogil functions. Conclusion Naturallanguageprocessing (NLP) programs have some peculiar performance characterstics. But the state object had a complicated interface, and was implemented as a cdef class.
By leveraging powerful Machine Learning algorithms, Generative AI models can create novel content such as images, text, audio, and even code. Founded in 2015, the company has developed some of the most advanced language models in existence, including GPT-3 and DALL-E.
Here is a brief description of the algorithm: OpenAI collected prompts submitted by the users to the earlier versions of the model. This not only makes the system extremely biased by also makes it more of an intelligent search algorithm than a truly intelligent system. Follow me on LinkedIn if you like my stories.
For example, building algorithms that run on our cameras and detect if somebody is coming home, or if a package gets delivered for you. The voice remote was launched for Comcast in 2015. We also have a team focused on the Digital Home and the applications of AI inside of it. And finally, also, AI/ML innovation and educational efforts.
For example, building algorithms that run on our cameras and detect if somebody is coming home, or if a package gets delivered for you. The voice remote was launched for Comcast in 2015. We also have a team focused on the Digital Home and the applications of AI inside of it. And finally, also, AI/ML innovation and educational efforts.
Recent Intersections Between Computer Vision and NaturalLanguageProcessing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and NaturalLanguageProcessing (NLP). Thus the algorithm is alignment-free.
These specialized processing units allow data scientists and AI practitioners to train complex models faster and at a larger scale than traditional hardware, propelling advancements in technologies like naturallanguageprocessing, image recognition, and beyond. What are Tensor Processing Units (TPUs)?
Fully Sharded Data Parallel (FSDP) – This is a type of data parallel training algorithm that shards the model’s parameters across data parallel workers and can optionally offload part of the training computation to the CPUs. This fine-tuning process involves providing the model with a dataset specific to the target domain. 3B is False.
If you were doing text analytics in 2015, you were probably using word2vec. al, 2015) is a new twist on word2vec that lets you learn more interesting, detailed and context-sensitive word vectors. So when Trask et al (2015) published a nice set of experiments showing that the idea worked well, we were easy to convince.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content