This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Discover Llama 4 models in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the Amazon SageMaker Python SDK. Alternatively, you can use the SageMaker Python SDK to programmatically access and use SageMaker JumpStart models. billion to a projected $574.78
This post explains how transition-based dependency parsers work, and argues that this algorithm represents a break-through in natural language understanding. A concise sample implementation is provided, in 500 lines of Python, with no external dependencies. In 2015 this type of parser is now increasingly dominant.
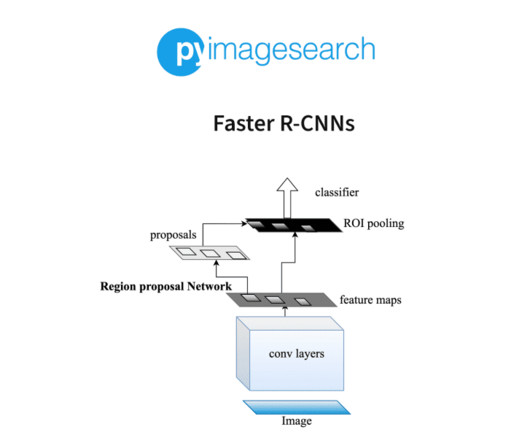
One of the most popular deep learning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al. Since then, the R-CNN algorithm has gone through numerous iterations, improving the algorithm with each new publication and outperforming traditional object detection algorithms (e.g.,
Reserve your seat now AIM406: Attain ML excellence with proficiency in Amazon SageMaker Python SDK December Wednesday 4 |4:30 PM – 5:30 PM In this comprehensive code talk, delve into the robust capabilities of the Amazon SageMaker Python SDK.
For example, to use the RedPajama dataset, use the following command: wget [link] python nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms.
Switching gears, imagine yourself being part of a high-tech research lab working with Machine Learning algorithms. Container runtimes are consistent, meaning they would work precisely the same whether you’re on a Dell laptop with an AMD CPU, a top-notch MacBook Pro , or an old Intel Lenovo ThinkPad from 2015. What Are Containers?
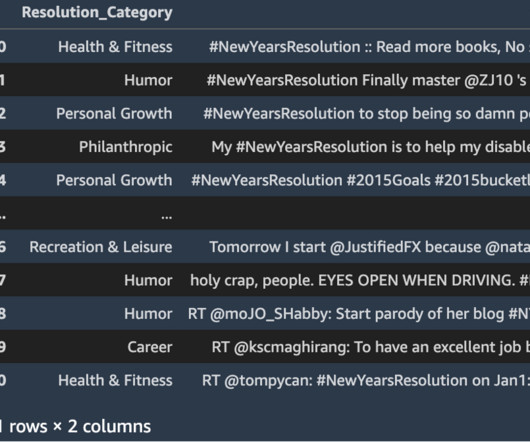
SageMaker JumpStart is the ML hub of Amazon SageMaker that provides access to pre-trained foundation models (FMs), LLMs, built-in algorithms, and solution templates to help you quickly get started with ML. For this solution, we use the 2015 New Year’s Resolutions dataset to classify resolutions.
Basically crack is a visible entity and so image-based crack detection algorithms can be adapted for inspection. Deep learning algorithms can be applied to solving many challenging problems in image classification. Deep learning algorithms can be applied to solving many challenging problems in image classification. Yi, and J.-K.
AI drawing generators use machine learning algorithms to produce artwork What is AI drawing? You might think of AI drawing as a generative art where the artist combines data and algorithms to create something completely new. The language model for Stable Diffusion is a transformer, and it is implemented in Python.
Although the internal algorithms within Amazon Personalize have been chosen based on Amazon’s experience in the machine learning space, a personalized model doesn’t come pre-loaded with any sort of data and trains models on a customer-by-customer basis. For this post, we choose Python (User-Defined Function). DOI= [link]
People don’t even need the in-depth knowledge of the various machine learning algorithms as it contains pre-built libraries. It supports languages like Python and R and processes the data with the help of data flow graphs. It is an open-source framework that is written in Python and can efficiently operate on both GPUs and CPUs.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., Understanding the robustness of image segmentation algorithms to adversarial attacks is critical for ensuring their reliability and security in practical applications.
Sometimes it’s a story of creating a superalgorithm that encapsulates decades of algorithmic development. One very simple example (introduced in 2015) is Nothing : Another, introduced in 2020, is Splice : An old chestnut of Wolfram Language design concerns the way infinite evaluation loops are handled. Let’s start with Python.
The most common techniques used for extractive summarization are term frequency-inverse document frequency (TF-IDF), sentence scoring, text rank algorithm, and supervised machine learning (ML). Use the evaluation algorithm with either built-in or custom datasets to evaluate your LLM model.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. Try the new interactive demo to explore similarities and compare them between 2015 and 2019 sense2vec (Trask et. Interestingly, “to ghost” wasn’t very common in 2015.
TensorFlow The Google Brain team created the open-source deep learning framework TensorFlow, which was made available in 2015. TensorFlow implements a wide range of deep learning and machine learning algorithms and is well-known for its adaptability and extensive ecosystem.
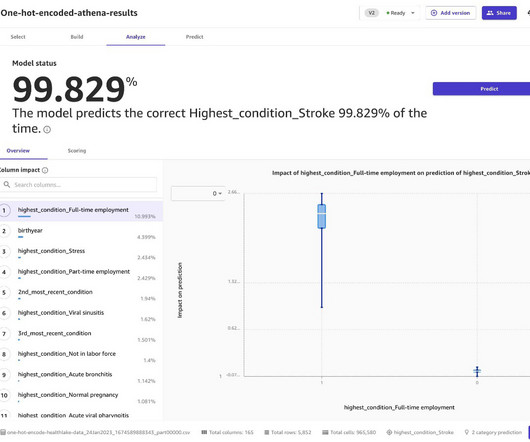
One of the challenges of working with categorical data is that it is not as amenable to being used in many machine learning algorithms. To overcome this, we use one-hot encoding, which converts each category in a column to a separate binary column, making the data suitable for a wider range of algorithms.
Solution overview In the following sections, we provide a step-by-step demonstration for fine-tuning an LLM for text generation tasks via both the JumpStart Studio UI and Python SDK. learning_rate – Controls the step size or learning rate of the optimization algorithm during training.
Note : This blog is more biased towards python as it is the language most developers use to get started in computer vision. Python / C++ The programming language to compose our solution and make it work. Why Python? Easy to Use: Python is easy to read and write, which makes it suitable for beginners and experts alike.
In practice, the rule-finding algorithm is a bit more complex, since there may be multiple shared substrings. This is accounted for by using a recursive version of the algorithm above. Rather than simply replacing the string afge by af , we apply the algorithm to these two substrings as well. a prefix of length n ; 2.
pip install dicom2nifti In a Python shell type: import dicom2nifti dicom2nifti.convert_directory("path to.dcm images"," path where results to be stored") And boom! This algorithm also does tissue chopping to remove computational complexities. This particular algorithm is not restricted to human anatomy.
Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects. It advances the scalability of ML in real-world applications by using algorithms to improve model performance and reproducibility. What is MLOps?
The pay-off is the.pipe() method, which adds data-streaming capabilities to spaCy: import spacy nlp = spacy.load('de') for doc in nlp.pipe(texts, n_threads=16, batch_size=10000): analyse_text(doc) My favourite post on the Zen of Python iterators was written by Radim, the creator of Gensim. The Python unicode object is also very useful.
Discover its dynamic computational graphs, ease of debugging, strong community support, and seamless integration with popular Python libraries for enhanced development. Pythonic Nature PyTorch is designed to be intuitive and closely resembles standard Python programming.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
The Allen Institute for AI introduced Semantic Scholar way back in 2015; it was among the earliest platforms to rank and predict research relevance with machine learning rather than raw citation counts. Going from a demo in a Jupyter notebook (used to write Python code) to getting something that can run at scale is a lot of work.
billion in 2015 and reached around $26.50 Explore their features, functionalities, and best practices for creating reports, dashboards, and visualizations. Develop programming skills: Enhance your programming skills, particularly in languages commonly used in BI development such as SQL, Python, or R. billion in 2021.
Solution overview In the following sections, we provide a step-by-step demonstration for fine-tuning an LLM for text generation tasks via both the JumpStart Studio UI and Python SDK. learning_rate – Controls the step size or learning rate of the optimization algorithm during training.
There is no need to be a Python programmer or to have an advanced degree in mathematics or computer science (although these things certainly don’t hurt). Through various algorithms, the tree places records from the data set into binary groups (yes/no, 0/1, true/false) until a final designation is achieved.
We can ask the model to generate a python function or a recipe for a cheesecake. Here is a brief description of the algorithm: OpenAI collected prompts submitted by the users to the earlier versions of the model. This approach with the rewards system based on human feedback is applied to GPT3 to create InstructGPT.
But I want to at least give our perspective on what motivated us back in 2015 to start talking about this and to start studying it back at Stanford, where the Snorkel team started: this idea of a shift from model-centric to data-centric AI development. So we’re going to be hearing about lots of topics.
But I want to at least give our perspective on what motivated us back in 2015 to start talking about this and to start studying it back at Stanford, where the Snorkel team started: this idea of a shift from model-centric to data-centric AI development. So we’re going to be hearing about lots of topics.
Dataset Overview 🌫 Air Quality Data in India (20152020) 📌 Link: DATASET 📝 Overview This dataset contains daily air quality data from major cities across India, collected between 2015 and 2020. It includes concentrations of various pollutants, meteorological parameters, and calculated AQI values.
We add the following to the end of the prompt: provide the response in json format with the key as “class” and the value as the class of the document We get the following response: { "class": "ID" } You can now read the JSON response using a library of your choice, such as the Python JSON library. The following image is of a gearbox.
We then also cover how to fine-tune the model using SageMaker Python SDK. FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2 models using the SageMaker Python SDK. You can access the Meta Llama 3.2
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content