This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
Discover Llama 4 models in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the Amazon SageMaker Python SDK. Alternatively, you can use the SageMaker Python SDK to programmatically access and use SageMaker JumpStart models. billion to a projected $574.78
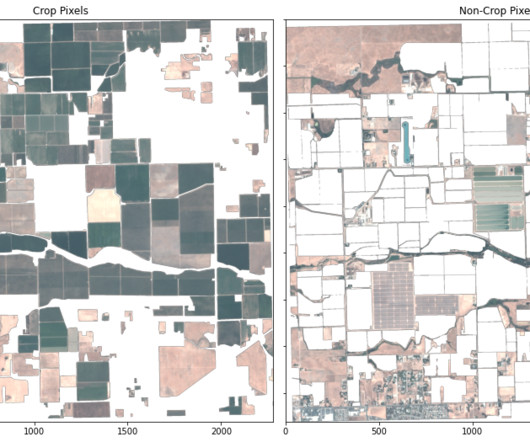
In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image. Identifying crop regions is a core step towards gaining agricultural insights, and the combination of rich geospatial data and ML can lead to insights that drive decisions and actions.
Michael Galarnyk, Learning Instructor | PhD Student at LinkedIn | GeorgiaTech Michael is a machine learning educator and PhD student at Georgia Tech researching ML for financial markets. He has taught Python and ML since 2015 through LinkedIn Learning, Stanford, andUCSD.
It supports languages like Python and R and processes the data with the help of data flow graphs. It is an open-source framework that is written in Python and can efficiently operate on both GPUs and CPUs. Keras supports a high-level neural network API written in Python. It is an open source framework.
Envision yourself as an ML Engineer at one of the world’s largest companies. You make a Machine Learning (ML) pipeline that does everything, from gathering and preparing data to making predictions. This is suitable for making a variety of Python applications with other dependencies being added to it at the user’s convenience.
Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python , Java, and Scala. On the server side, runtimes include Python, Java, and Scala in the warehouse model or Snowpark Container Services (private preview). Why is Snowpark Exciting to us?
Meesho was founded in 2015 and today focuses on buyers and sellers across India. We used AWS machine learning (ML) services like Amazon SageMaker to develop a powerful generalized feed ranker (GFR). SageMaker offered ease of deployment with support for various ML frameworks, allowing models to be served with low latency.
Rumelhart Prize in 2015, and the ACM/AAAI Allen Newell Award in 2009. He received the Ulf Grenander Prize from the American Mathematical Society in 2021, the IEEE John von Neumann Medal in 2020, the IJCAI Research Excellence Award in 2016, the David E.
Natural language processing (NLP) is the field in machine learning (ML) concerned with giving computers the ability to understand text and spoken words in the same way as human beings can. You will learn how to use the SageMaker Jumpstart UI and SageMaker Python SDK to deploy the solution and run inference using the available models.
In today’s highly competitive market, performing data analytics using machine learning (ML) models has become a necessity for organizations. For example, in the healthcare industry, ML-driven analytics can be used for diagnostic assistance and personalized medicine, while in health insurance, it can be used for predictive care management.
In today’s blog, we will explore the Netflix dataset using Python and uncover some interesting insights. In this blog, we’ll be using Python to perform exploratory data analysis (EDA) on a Netflix dataset that we’ve found on Kaggle. Submission Suggestions Netflix Data Analysis using Python was originally published in MLearning.ai
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Today, 35% of companies report using AI in their business, which includes ML, and an additional 42% reported they are exploring AI, according to the IBM Global AI Adoption Index 2022. What is MLOps?
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning. Clay Elmore is an AI/ML Specialist Solutions Architect at AWS.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. At this event, SPIE member Light and Light-based Technologies (IYL 2015). The endorsement for a Day of Light has been embraced by SPIE and other founding partners of IYL 2015.
This guarantees businesses can fully utilize deep learning in their AI and ML initiatives. You can make more informed judgments about your AI and ML initiatives if you know these platforms' features, applications, and use cases. Integration: Strong integration with Python, supporting popular libraries such as NumPy and SciPy.
describe() count 9994 mean 2017-04-30 05:17:08.056834048 min 2015-01-03 00:00:00 25% 2016-05-23 00:00:00 50% 2017-06-26 00:00:00 75% 2018-05-14 00:00:00 max 2018-12-30 00:00:00 Name: Order Date, dtype: object Average sales per year df['year'] = df['Order Date'].apply(lambda Latest order date. Yearly average sales.
JumpStart helps you quickly and easily get started with machine learning (ML) and provides a set of solutions for the most common use cases that can be trained and deployed readily with just a few steps. Defining hyperparameters involves setting the values for various parameters used during the training process of an ML model.
Launched in 2015 and becoming a nonprofit organization in 2020, WiBD is a grassroots initiative dedicated to inspiring, connecting, and advancing women in data fields. Currently, there is an ML Engineer Track, but no certification is available yet. We provided a quick overview of Women in Big Data (WiBD). link] com/certification.
2015; Huang et al., 2015), which consists of 20 object categories with varying levels of complexity. We implemented the MBD approach using the Python programming language, with the scikit-learn and NetworkX libraries for feature selection and structure learning, respectively. 2012; Otsu, 1979; Long et al., 2018; Pang et al.,
pip install dicom2nifti In a Python shell type: import dicom2nifti dicom2nifti.convert_directory("path to.dcm images"," path where results to be stored") And boom! Koltun, “Multi-scale context aggregation by dilated convolutions,” arXiv preprint arXiv:1511.07122, 2015. [4] dcm format. Conversion of images from .dcm
Note : This blog is more biased towards python as it is the language most developers use to get started in computer vision. Python / C++ The programming language to compose our solution and make it work. Why Python? Easy to Use: Python is easy to read and write, which makes it suitable for beginners and experts alike.
SpaCy is a popular open-source NLP library developed in 2015 by Matthew Honnibal and Ines Montani, the founders of the software company Explosion. We can do this using pip, a package manager for Python: pip install spacy Step 2: Load the SpaCy model We also need to download a pre-trained language model for SpaCy. What is SpaCy?
The most common techniques used for extractive summarization are term frequency-inverse document frequency (TF-IDF), sentence scoring, text rank algorithm, and supervised machine learning (ML). Hurricane Patricia has been rated as a categor… Human: 23 October 2015 Last updated at 17:44 B… [{‘name’: meteor’, “value’: 0.102339181286549.
JumpStart helps you quickly and easily get started with machine learning (ML) and provides a set of solutions for the most common use cases that can be trained and deployed readily with just a few steps. Defining hyperparameters involves setting the values for various parameters used during the training process of an ML model.
We will discuss how models such as ChatGPT will affect the work of software engineers and ML engineers. Will ChatGPT replace ML Engineers? We can ask the model to generate a python function or a recipe for a cheesecake. Will ChatGPT replace ML Engineers? We will answer the question “ Will you lose your job?”
His presentation also highlights the ways that Snorkel’s platform, Snorkel Flow, enables users to rapidly and programmatically label and develop datasets and then use them to train ML models. And so this leads to this constant iteration of labeling and relabeling and reshaping and redeveloping the data that fuels and determines ML models.
His presentation also highlights the ways that Snorkel’s platform, Snorkel Flow, enables users to rapidly and programmatically label and develop datasets and then use them to train ML models. And so this leads to this constant iteration of labeling and relabeling and reshaping and redeveloping the data that fuels and determines ML models.
Dataset Overview 🌫 Air Quality Data in India (20152020) 📌 Link: DATASET 📝 Overview This dataset contains daily air quality data from major cities across India, collected between 2015 and 2020. It includes concentrations of various pollutants, meteorological parameters, and calculated AQI values.
We add the following to the end of the prompt: provide the response in json format with the key as “class” and the value as the class of the document We get the following response: { "class": "ID" } You can now read the JSON response using a library of your choice, such as the Python JSON library. The following image is of a gearbox.
in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the SageMaker Python SDK. SageMaker Studio is a comprehensive IDE that offers a unified, web-based interface for performing all aspects of the machine learning (ML) development lifecycle. Discover Meta SAM 2.1 Deploy Meta SAM 2.1
Solution overview SageMaker JumpStart is a robust feature within the SageMaker machine learning (ML) environment, offering practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs). We then also cover how to fine-tune the model using SageMaker Python SDK. You can access the Meta Llama 3.2
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content