This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From vCenter, administrators can configure and control ESXi hosts, datacenters, clusters, traditional storage, software-defined storage, traditional networking, software-defined networking, and all other aspects of the vSphere architecture. VMware “clustering” is purely for virtualization purposes.
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. Industrial Internet of Things (IIoT) The Constraints Within the area of Industry 4.0,
Presumably due to this fact, Andrew Ng, in his presentation in NeurIPS 2016, gave a rough and abstract predictions of how transfer learning in machine learning would make commercial success like white lines in the figure below. But only with limited labeled data, decision boundaries would be ambiguous.
If you are a Data Scientist, then your LinkedIn profile should be flooded with information on DataScience’s latest development in this domain, such that it instantly garners the attention of recruiters as well as your contemporaries. is a trusted e-learning platform for DataScience.
Databricks Databricks is the developer of Delta Lake, an open-source project that brings reliability to data lakes for machine learning and other cases. Their platform was developed for working with Spark and provides automated cluster management and Python-style notebooks. This was further proven with the release of GPT-4 last March.
By utilizing insights found in the images, not previously available in the tabular data, we can improve the accuracy of the model. Both the images and tabular data discussed in this post were originally made available and published to GitHub by Ahmed and Moustafa (2016). in DataScience. and 5.498, respectively.
The first project we did used NLP for finance contracts (this was 2016). It’s petabytes of data, so a lot of my time is spent processing it. I mostly use U-SQL, a mix between C# and SQL that can distribute in very large clusters. In 2022 I actually joined the lab and here we are today. I use PyTorch for that.
Image generated with Midjourney In today’s fast-paced world of datascience, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust data pipelines.
Inference example Output from GPT-J 6B Before Fine-Tuning Output from GPT-J 6B After Fine-Tuning This Form 10-K report shows that This Form 10-K report shows that: The Companys net income attributable to the Company for the year ended December 31, 2016 was $3,923,000, or $0.21 per diluted share, compared to $3,818,000, or $0.21
These algorithms help legal professionals swiftly discover essential information, speed up document review, and assure comprehensive case analysis through approaches such as document clustering and topic modeling. Artificial intelligence in law: The state of play 2016. Thomson Reuters Legal Executive Institute.
Inference example Output from GPT-J 6B Before Fine-Tuning Output from GPT-J 6B After Fine-Tuning This Form 10-K report shows that This Form 10-K report shows that: The Companys net income attributable to the Company for the year ended December 31, 2016 was $3,923,000, or $0.21 per diluted share, compared to $3,818,000, or $0.21
First released in 2016, it quickly gained traction due to its intuitive design and robust capabilities. Scalability TensorFlow can handle large datasets and scale to distributed clusters, making it suitable for training complex models. This scalability is crucial for applications that require processing vast amounts of data.
Most solvers were datascience professionals, professors, and students, but there were also many data analysts, project managers, and people working in public health and healthcare. Silas Falde is a sophomore undergraduate at the University of Michigan School of Engineering studying DataScience. Alejandro A.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






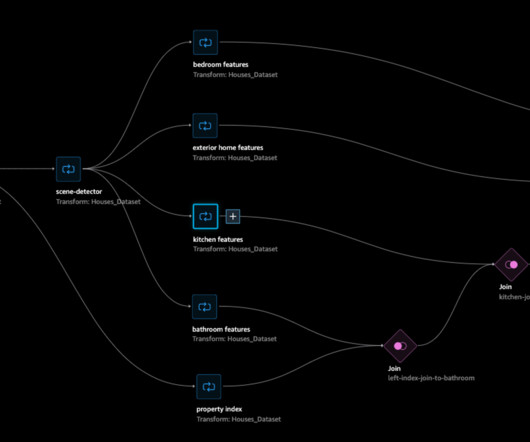













Let's personalize your content