This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Read about the research groups at CDS working to advance datascience and machine learning! CDS includes a range of research groups that bring together NYU professors, faculty fellows, and PhD students working at various intersections of datascience, machine learning, and artificial intelligence.
For instance, in naturallanguageprocessing, a model trained on various languages might be tasked with translating a language it has never seen before. This comprehensive evaluation sheds light on the landscape of zero-shot learning methodologies, exploring the strengths and challenges across various approaches.
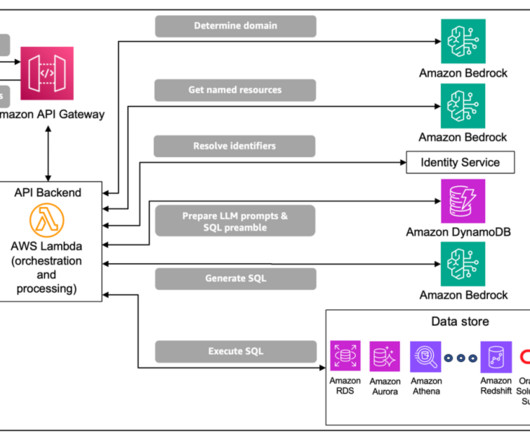
Managing identifiers for SQL generation (resource IDs) Resolving identifiers involves extracting the named resources, as named entities, from the users query and mapping the values to unique IDs appropriate for the target data source prior to NL2SQL generation. Toby also leads a program training the next generation of AI Solutions Architects.
In the ever-evolving landscape of naturallanguageprocessing (NLP), embedding techniques have played a pivotal role in enhancing the capabilities of language models. Fast forward to 2016, Facebook’s FastText introduced a significant shift by considering sub-word information.
For instance, in naturallanguageprocessing, a model trained on various languages might be tasked with translating a language it has never seen before. This comprehensive evaluation sheds light on the landscape of zero-shot learning methodologies, exploring the strengths and challenges across various approaches.
All of these companies were founded between 2013–2016 in various parts of the world. Soon to be followed by large general language models like BERT (Bidirectional Encoder Representations from Transformers).
Context (Snippet from PDF file) Question Answer THIS STRATEGIC ALLIANCE AGREEMENT (Agreement) is made and entered into as of November 6, 2016 (the Effective Date) by and between Dialog Semiconductor (UK) Ltd., With a background in AI/ML, datascience, and analytics, Yunfei helps customers adopt AWS services to deliver business results.
Presumably due to this fact, Andrew Ng, in his presentation in NeurIPS 2016, gave a rough and abstract predictions of how transfer learning in machine learning would make commercial success like white lines in the figure below. My point is, the more data you have, and the bigger computation resource you have, the better performance you get.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately?
His research is developing SAFE (secure & private, auditable, fair, and equitable) theoretical approaches and practical frameworks to leverage the power of data to solve real-world problems. Shaishav Jain is a DataScience Associate Consultant at ZS. Hafiz Asif is a postdoc at I-DSLA. He received his Ph.D.
Institute of Analytics The Institute of Analytics is a non-profit organization that provides datascience and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic datascience concepts to advanced machine learning techniques.
With the emergence of datascience and AI, clustering has allowed us to view data sets that are not easily detectable by the human eye. Thus, this type of task is very important for exploratory data analysis. 1207–1221, May 2016, doi: 10.1109/JSAC.2016.2545384. 2016.2545384. BECOME a WRITER at MLearning.ai
Jan 22: Ines was invited as a guest to the TalkPython podcast and discussed how to build a datascience startup. Mar 29: Ines joined the at the German Python Podcast to talk about NaturalLanguageProcessing with spaCy. ? Since founding Explosion in 2016, we’ve run the company as a profitable business.
Further Reading TensorFlow Documentation TensorFlow Tutorials PyTorch PyTorch, developed by Facebook's AI Research Lab (FAIR) , was released in 2016. Libraries and Extensions: Includes torchvision for image processing, touchaudio for audio processing, and torchtext for NLP. Notable Use Cases in the Industry H2O.ai
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
Visual Question Answering (VQA) stands at the intersection of computer vision and naturallanguageprocessing, posing a unique and complex challenge for artificial intelligence. is a significant benchmark dataset in computer vision and naturallanguageprocessing. or Visual Question Answering version 2.0,
First released in 2016, it quickly gained traction due to its intuitive design and robust capabilities. In industry, it powers applications in computer vision, naturallanguageprocessing, and reinforcement learning. It excels in image classification, naturallanguageprocessing, and time series forecasting applications.
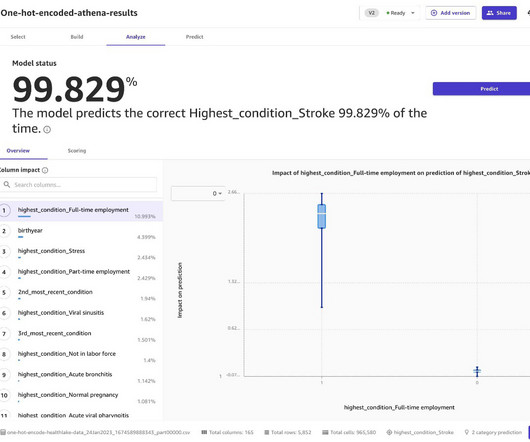
However, organizations and users in industries where there is potential health data, such as in healthcare or in health insurance, must prioritize protecting the privacy of people and comply with regulations. Use Amazon Athena queries for the following: Extract non-sensitive structured data from Amazon HealthLake.
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
Read More: Top 7 Generative AI Use Cases and Application Hugging Face Hugging Face is a New York-based AI research company that is best known for its work on open-source naturallanguageprocessing (NLP) models.
Most solvers were datascience professionals, professors, and students, but there were also many data analysts, project managers, and people working in public health and healthcare. I love participating in various competitions involving deep learning, especially tasks involving naturallanguageprocessing or LLMs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content