This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
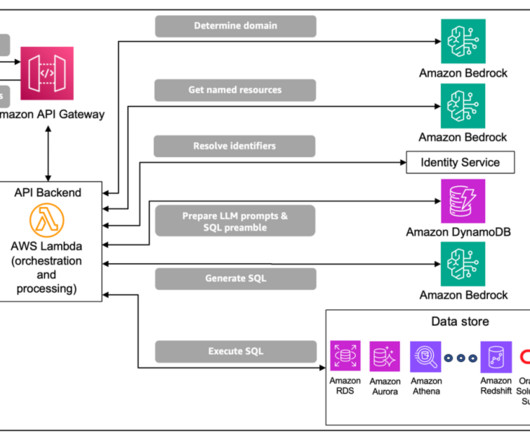
The API is linked to an AWS Lambda function, which implements and orchestrates the processing steps described earlier using a programming language of the users choice (such as Python) in a serverless manner. Thomas Matthew is an AL/ML Engineer at Cisco. Daniel Vaquero is a Senior AI/ML Specialist Solutions Architect at AWS.
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for data science, machine learning (ML), and computational science. Given the importance of Jupyter to data scientists and ML developers, AWS is an active sponsor and contributor to Project Jupyter.
Discover Llama 4 models in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the Amazon SageMaker Python SDK. Alternatively, you can use the SageMaker Python SDK to programmatically access and use SageMaker JumpStart models. billion to a projected $574.78
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).
We use DSPy (Declarative Self-improving Python) to demonstrate the workflow of Retrieval Augmented Generation (RAG) optimization, LLM fine-tuning and evaluation, and human preference alignment for performance improvement. Examples are similar to Python dictionaries but with added utilities such as the dspy.Prediction as a return value.
Founded in 2016 by the creator of Apache Zeppelin, Zepl provides a self-service data science notebook solution for advanced data scientists to do exploratory, code-centric work in Python, R, and Scala. It was built with enterprise-ready features such as collaboration, versioning, and security. Stay tuned.
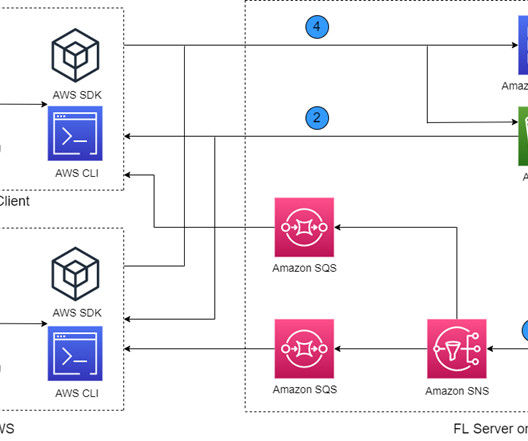
Machine learning (ML), especially deep learning, requires a large amount of data for improving model performance. It is challenging to centralize such data for ML due to privacy requirements, high cost of data transfer, or operational complexity. The ML framework used at FL clients is TensorFlow.
He received the Ulf Grenander Prize from the American Mathematical Society in 2021, the IEEE John von Neumann Medal in 2020, the IJCAI Research Excellence Award in 2016, the David E. His research interests bridge the computational, statistical, cognitive, biological, and social sciences.
The task involved writing Python code to read data, transform it, and then visualize it in an interesting map. Read and summarize the data To give the agent context about the dataset, we prompt Claude 2 to write Python code that reads the data and provides a summary relevant to our task. The full list is available in the prompts.py
Solution overview In this blog, we will walk through the following scenarios : Deploy Llama 2 on AWS Inferentia instances in both the Amazon SageMaker Studio UI, with a one-click deployment experience, and the SageMaker Python SDK. Fine-tune Llama 2 on Trainium instances in both the SageMaker Studio UI and the SageMaker Python SDK.
In today’s highly competitive market, performing data analytics using machine learning (ML) models has become a necessity for organizations. For example, in the healthcare industry, ML-driven analytics can be used for diagnostic assistance and personalized medicine, while in health insurance, it can be used for predictive care management.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
How to read an image in Python using OpenCV — 2023 2. Rotating and Scaling Images using cv2 — a fun Python application — 2023 5. How to use mouse clicks to draw circles in Python using OpenCV — easy project — 2023 6. How to use mouse clicks to draw circles in Python using OpenCV — easy project — 2023 6.
These pipelines cover the entire lifecycle of an ML project, from data ingestion and preprocessing, to model training, evaluation, and deployment. Adopted from [link] In this article, we will first briefly explain what ML workflows and pipelines are. around the world to streamline their data and ML pipelines.
This guarantees businesses can fully utilize deep learning in their AI and ML initiatives. You can make more informed judgments about your AI and ML initiatives if you know these platforms' features, applications, and use cases. Integration: Strong integration with Python, supporting popular libraries such as NumPy and SciPy.
JumpStart helps you quickly and easily get started with machine learning (ML) and provides a set of solutions for the most common use cases that can be trained and deployed readily with just a few steps. Defining hyperparameters involves setting the values for various parameters used during the training process of an ML model.
Python, Data Mining, Analytics and ML are one of the most preferred skills for a Data Scientist. For example, if you are a Data Scientist, then you should add keywords like Python, SQL, Machine Learning, Big Data and others. Expansive Hiring The IT and service sector is actively hiring Data Scientists. Wrapping it up !!!
describe() count 9994 mean 2017-04-30 05:17:08.056834048 min 2015-01-03 00:00:00 25% 2016-05-23 00:00:00 50% 2017-06-26 00:00:00 75% 2018-05-14 00:00:00 max 2018-12-30 00:00:00 Name: Order Date, dtype: object Average sales per year df['year'] = df['Order Date'].apply(lambda Yearly average sales. Convert it into a graph.
In 2016, Google released an open-source software called AutoML. Some common coding languages include C++, Java, Python , and SQL. Finally, machine learning (ML) is also being used to write code. ML is a type of AI that allows systems to learn from data and improve their performance over time.
Abstract Polars is a fast-growing open-source data frame library that is rapidly becoming the preferred choice for data scientists and data engineers in Python. It is available in multiple languages: Python, Rust, and NodeJS. If you are looking for a fast and intuitive data frame library for Python, then Polars is a great option.
The “Fourth Industrial Revolution” was coined by Klaus Schwab of the World Economic Forum in 2016. Python is unarguably the most broadly used programming language throughout the data science community. Native Python Support for Snowpark. Consuming AI/ML Insights for Faster Decision Making.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. You can use either method to generate the linearized text from the document using the latest version of Amazon Textract Textractor Python library.
2016) Data Management : By allowing clustering to occur locally, edge devices in the network can enable near-real-time data analysis in order to make data-driven decisions Energy : Clustering methods have been known to be more energy efficient when it comes to data transmission and processing (Loganathan & Arumugan, 2021). 2016.2545384.
It was so much easier when one just needed to know python, sci-kit learn, pandas, tensorflow, and pytorch. The number of AI applications and programming languages that one needs to know to stay competent has drastically increased. Google Apps Scripts is a combination of Javascript and html, the Google scripts scripting language (.gs)
JumpStart helps you quickly and easily get started with machine learning (ML) and provides a set of solutions for the most common use cases that can be trained and deployed readily with just a few steps. Defining hyperparameters involves setting the values for various parameters used during the training process of an ML model.
Here's an example of calculating feature importance using permutation importance with scikit-learn in Python: from sklearn.inspection import permutation_importance # Fit your model (e.g., Alibi Alibi is an open-source Python library for algorithmic transparency and interpretability. Russell, C. & & Watcher, S. Singh, S. &
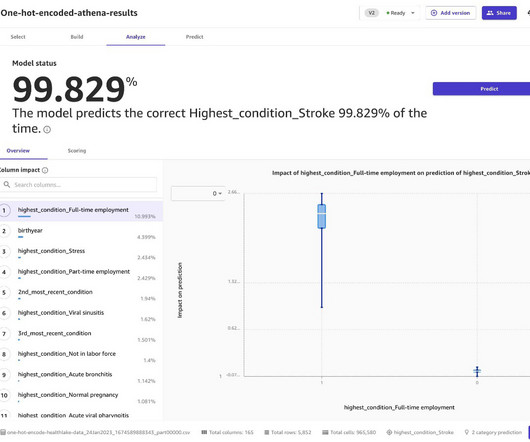
In the fraud detection example, to effectively translate ML metrics into business-relevant information, we need to understand how the model’s behavior impacts business objectives. In other words, the outcomes of ML models should be equitable across different groups, even if there were historical biases in the training data.
We implemented the MBD approach using the Python programming language, with the scikit-learn and NetworkX libraries for feature selection and structure learning, respectively. 2018; Papernot et al., We also ensured that the selected images were not part of the training set for the MBD model, to avoid any bias in the results. Papernot, N.,
A Simple Step-to-Step Guide to Chi-Square Tests in Python Introduction In our last article , we used the t-test. Photo by Mikhail Nilov on Pixels Overview In this article, we will provide a step-to-step guide on how to perform Chi-Square tests in Python. 2016) Statistics in Plain English. We will accept the null hypothesis.
This API call can literally be anything, e.g. executing a Python script, calling another neural network, and so on. When detecting the execute API token “→” the decoding process is interrupted and the API is called with its input. You name it. In the end, the response just needs to be a single text sequence. 2020 ), SVAMP ( Patel et al.,
Solution overview SageMaker JumpStart is a robust feature within the SageMaker machine learning (ML) environment, offering practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs). We then also cover how to fine-tune the model using SageMaker Python SDK. You can access the Meta Llama 3.2
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content