This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
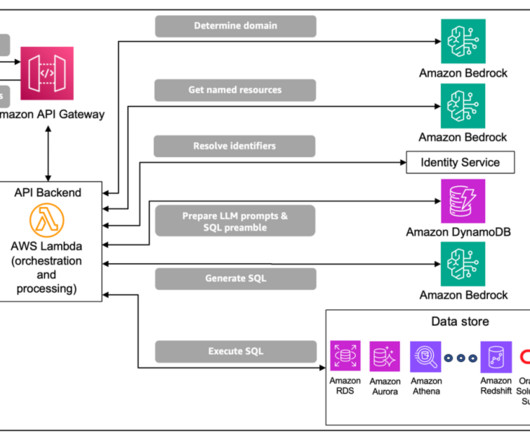
This can be implemented using naturallanguageprocessing (NLP) or LLMs to apply named entity recognition (NER) capabilities to drive the resolution process. This optional step has the most value when there are many named resources and the lookup process is complex.
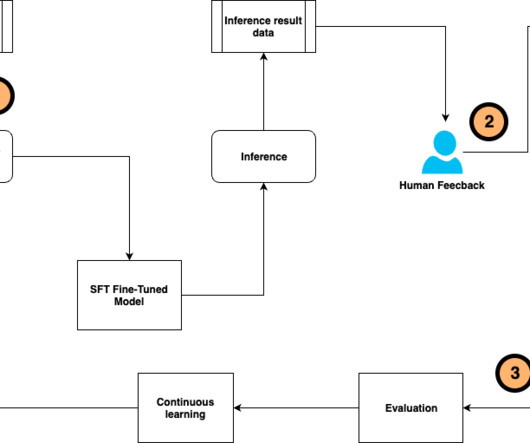
In this post, we introduce the continuous self-instruct fine-tuning framework and its pipeline, and present how to drive the continuous fine-tuning process for a question-answer task as a compound AI system. Examples are similar to Python dictionaries but with added utilities such as the dspy.Prediction as a return value.
This is a guest post by Wah Loon Keng , the author of spacy-nlp , a client that exposes spaCy ’s NLP text parsing to Node.js (and other languages) via Socket.IO. NaturalLanguageProcessing and other AI technologies promise to let us build applications that offer smarter, more context-aware user experiences. CLI: 2.4.0,
Solution overview In this blog, we will walk through the following scenarios : Deploy Llama 2 on AWS Inferentia instances in both the Amazon SageMaker Studio UI, with a one-click deployment experience, and the SageMaker Python SDK. Fine-tune Llama 2 on Trainium instances in both the SageMaker Studio UI and the SageMaker Python SDK.
A good understanding of Python and machine learning concepts is recommended to fully leverage TensorFlow's capabilities. Further Reading TensorFlow Documentation TensorFlow Tutorials PyTorch PyTorch, developed by Facebook's AI Research Lab (FAIR) , was released in 2016. It is well-suited for both research and production environments.
First released in 2016, it quickly gained traction due to its intuitive design and robust capabilities. In industry, it powers applications in computer vision, naturallanguageprocessing, and reinforcement learning. PythonicNature PyTorch is designed to be intuitive and closely resembles standard Python programming.
Mar 29: Ines joined the at the German Python Podcast to talk about NaturalLanguageProcessing with spaCy. ? ✨ Aug 12: We released Prodigy v1.11 , which includes a bunch of new features, including a new installation process via pip and new wheels for Python 3.9 September ?
In 2016, Google released an open-source software called AutoML. The code is written in a specific programming language which is then read by a computer to create the desired results. There are many different coding languages, each with its syntax and usage. Some common coding languages include C++, Java, Python , and SQL.
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
2016) Data Management : By allowing clustering to occur locally, edge devices in the network can enable near-real-time data analysis in order to make data-driven decisions Energy : Clustering methods have been known to be more energy efficient when it comes to data transmission and processing (Loganathan & Arumugan, 2021).
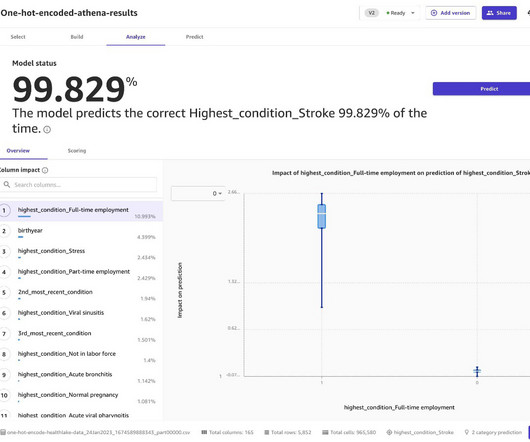
Use naturallanguageprocessing (NLP) in Amazon HealthLake to extract non-sensitive data from unstructured blobs. When he’s not modernizing workloads for global enterprises, Yann plays piano, tinkers in React and Python, and regularly YouTubes about his cloud journey. Use SageMaker Canvas for analytics and predictions.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. sense2vec reloaded: the updated library sense2vec is a Python package to load and query vectors of words and multi-word phrases based on part-of-speech tags and entity labels.
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. Analysis of publications containing accelerated compute workloads by Zeta-Alpha shows a breakdown of 91.5%
We implemented the MBD approach using the Python programming language, with the scikit-learn and NetworkX libraries for feature selection and structure learning, respectively. Generative adversarial networks-based adversarial training for naturallanguageprocessing. 2018; Papernot et al., Papernot, N.,
Transformers and transfer-learning NaturalLanguageProcessing (NLP) systems face a problem known as the “knowledge acquisition bottleneck”. 2019) have shown that a transformer models trained on only 1% of the IMDB sentiment analysis data (just a few dozen examples) can exceed the pre-2016 state-of-the-art.
We then also cover how to fine-tune the model using SageMaker Python SDK. FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2 models using the SageMaker Python SDK. You can access the Meta Llama 3.2
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content