This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
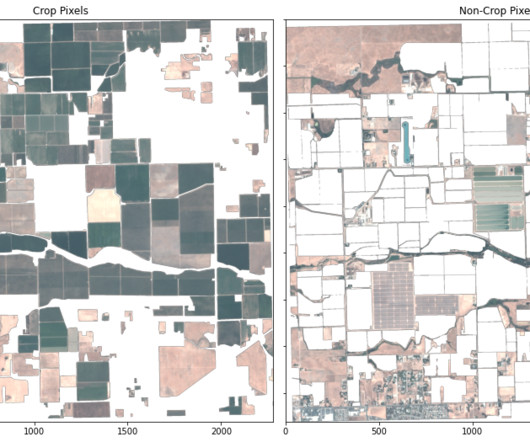
In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image. Identifying crop regions is a core step towards gaining agricultural insights, and the combination of rich geospatial data and ML can lead to insights that drive decisions and actions.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. In this post, we deep dive into the technical details of this ML model.
PMLR, 2017. [2] arXiv preprint arXiv:1710.09412 (2017). [7] CrossValidated] Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners. References [1] Guo, Chuan, et al. “
For example, if you are using regularization such as L2 regularization or dropout with your deep learning model that performs well on your hold-out-cross-validation set, then increasing the model size won’t hurt performance, it will stay the same or improve. machine-learning-yearning-book (2017). [2]. References [1].Ng,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content