This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the dynamic field of artificial intelligence, traditional machinelearning, reliant on extensive labeled datasets, has given way to transformative learning paradigms. Source: Photo by Hal Gatewood on Unsplash In this exploration, we navigate from the basics of supervisedlearning to the forefront of adaptive models.
To learn more about this topic, please consider attending our fourth annual PyData Berlin conference on June 30-July 2, 2017. The post How Faulty Data Breaks Your MachineLearning Process appeared first on Dataconomy. Miroslav Batchkarov and other experts will be giving talks.
Counting Shots, Making Strides: Zero, One and Few-Shot Learning Unleashed In the dynamic field of artificial intelligence, traditional machinelearning, reliant on extensive labeled datasets, has given way to transformative learning paradigms. Welcome to the frontier of machinelearning innovation!
First described in a 2017 paper from Google, transformers are among the newest and one of the most powerful classes of models invented to date. They’re driving a wave of advances in machinelearning some have dubbed transformer AI. Now we see self-attention is a powerful, flexible tool for learning,” he added. “Now
While we wouldn’t say bootstrapping is for everyone, it’s been a joy to build the company that we want to build, the way we want to build it: Worked with some amazing companies and shipped custom, cutting-edge machinelearning solutions for a range of exciting problems. spaCy’s MachineLearning library for NLP in Python.
Von Data Science spricht auf Konferenzen heute kaum noch jemand und wurde hype-technisch komplett durch MachineLearning bzw. GPT-3 ist jedoch noch komplizierter, basiert nicht nur auf Supervised Deep Learning , sondern auch auf Reinforcement Learning. Artificial Intelligence (AI) ersetzt.
We wrote this post while working on Prodigy , our new annotation tool for radically efficient machine teaching. Prodigy features many of the ideas and solutions for data collection and supervisedlearning outlined in this blog post. It’s a cloud-free, downloadable tool and comes with powerful active learning models.
We are going to explore these and other essential questions from the ground up , without assuming prior technical knowledge in AI and machinelearning. The core process is a general technique known as self-supervisedlearning , a learning paradigm that leverages the inherent structure of the data itself to generate labels for training.
In contrast to classification, a supervisedlearning paradigm, generation is most often done in an unsupervised manner: for example an autoencoder , in the form of a neural network, can capture the statistical properties of a dataset. One does not need to look into the math to see that it’s inherently more difficult.
Foundation Models (FMs), such as GPT-3 and Stable Diffusion, mark the beginning of a new era in machinelearning and artificial intelligence. Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. What is self-supervisedlearning?
Training machinelearning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervisedlearning (SSL). MachineLearning Engineer at AWS. Andrew Ang is a Sr.
Machinelearning systems are built from both code and data. That’s why we’re pleased to introduce Prodigy , a downloadable tool for radically efficient machine teaching. Machinelearning is an inherently uncertain technology, but the waterfall annotation process relies on accurate upfront planning.
Limited availability of labeled datasets: In some domains, there is a scarcity of datasets with fine-grained annotations, making it difficult to train segmentation networks using supervisedlearning algorithms. When evaluated on the MS COCO dataset test-dev 2017, YOLOv8x attained an impressive average precision (AP) of 53.9%
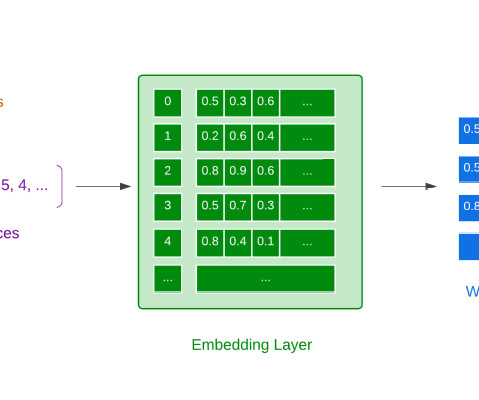
2017) paper, vector embeddings have become a standard for training text-based DL models. Data2Vec: A General Framework For Self-SupervisedLearning in Speech, Vision and Language. It is none other than the legendary Vector Embeddings! Without further ado, let’s dive right in! A vector embedding is an object (e.g., and Auli, M.,
Towards the end of my studies, I incorporated basic supervisedlearning into my thesis and picked up Python programming at the same time. I also started on my data science journey by attending the Coursera specialization by Andrew Ng — Deep Learning. That was in 2017. Getting the first job was the hardest.
I will begin with a discussion of language, computer vision, multi-modal models, and generative machinelearning models. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machinelearning (ML) research over the last decade.
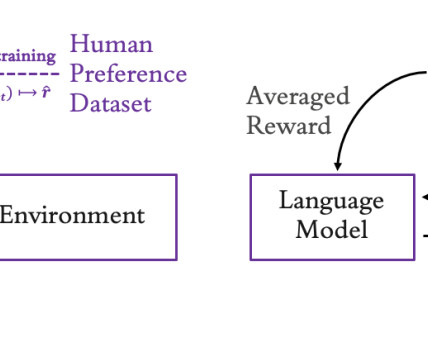
Supervisedlearning can help tune LLMs by using examples demonstrating some desired behaviors, which is called supervised fine-tuning (SFT). 2017) provided the first evidence that RLHF could be economically scaled up to practical applications. 2017) Deep reinforcement learning from human preferences.
The Transformer architecture 3 (Vaswani, 2017) was a breakthrough improvement on the encoder-decoder; it introduced the concept of self-attention , which allowed the model to focus its attention on different words on the input and output phrases.
LLMs are advanced AI systems that leverage machinelearning to understand and generate natural language. Evolution of LLMs One of the most notable technological advancements in LLMs is the introduction of the transformer architecture in 2017. What are large language models (LLMs)?
Technology and methodology DeepMind’s approach revolves around sophisticated machinelearning methods that enable AI to interact with its environment and learn from experience. AlphaGo Zero: This iteration used unsupervised reinforcement learning, allowing the program to exceed its predecessors consistently.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content