This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is why the Algorithmic Justice League, a nonprofit that sheds light on AI harms, launched a campaign this month called “Freedom Flyers” to raise awareness of your right to opt out. She was referring to a roadmap released in 2018 by the TSA. The TSA’s own 2018 roadmap says they aim to use “live biometrics” in the future.
A research project from Israel is helping solve the problem of overwhelming email messages by using big data algorithms to sort through email content more effectively. Mark Last, a professor with Ben Gurion University worked with his colleagues to develop some big data algorithms to summarize text more efficiently.
The Bureau of Labor Statistics reports that there were over 31,000 people working in this field back in 2018. You can also use your knowledge of big data to create AI algorithms that will prevent fraud in games that involve spending money. Are you looking to get a job in big data? That could be a wise career move.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
The landscape of blockchain-driven solutions: from 2018 to 2022. In 2018-2019, budding blockchain-based advertising projects provided the first opportunity to buy clean and secure traffic, enriched with genuine data about ad campaign performance. Globally, ad fraud will most certainly cost advertisers $81 billion in 2022.
The database was calibrated and validated using data from more than 400 trials in the region. Additionally, the database is enhanced with observations from satellite imagery, whereas zonal statistics are derived from spectral indices in order to represent spatio-temporal changes in vegetation, seen across geographies and phenological phases.
That’s because AI algorithms are trained on data. And it’s safe to say that most AI algorithms are trained on datasets that are significantly older. Worse yet, the AI’s bias would likely find its way into the system’s database and follow the students from one class to the next. You turned left or right.
Predictive analytics: Predictive analytics leverages historical data and statistical algorithms to make predictions about future events or trends. Cloud-based business intelligence (BI): Cloud-based BI tools enable organizations to access and analyze data from cloud-based sources and on-premises databases.
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). They’re mostly trained on general domain corpora, making them less effective on domain-specific tasks.
github.com Their core repos consist of SparseML: a toolkit that includes APIs, CLIs, scripts and libraries that apply optimization algorithms such as pruning and quantization to any neural network. Neural Magic Neural Magic has 6 repositories available. Follow their code on GitHub. SparseZoo: a model repo for sparse models. Connected Papers
After all, this is what machine learning really is; a series of algorithms rooted in mathematics that can iterate some internal parameters based on data. This is understandable: a report by PwC in 2018 suggested that 30% of UK jobs will be impacted by automation by the 2030s Will Robots Really Steal Our Jobs?
This dataset comprises a multi-center critical care database collected from over 200 hospitals, which makes it ideal to test our FL experiments. We used the eICU Collaborative Research Database , a multi-center intensive care unit (ICU) database, comprising 200,859 patient unit encounters for 139,367 unique patients.
2018, July). In IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium (pp. In the EU, database copyright only covers the structure of the database and not the contents, but the contents may have sui generis rights, though that is not clear and possibly varies with the method used to collect the data.
According to a report by Statista, the global data sphere is expected to reach 180 zettabytes by 2025 , a significant increase from 33 zettabytes in 2018. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos).
According to a report by Statista, the global data sphere is expected to reach 180 zettabytes by 2025 , a significant increase from 33 zettabytes in 2018. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos).
In November 2018, Marriott International announced that cyber thieves stole data on 500 million customers. Such technologies are well known, and algorithms and reliable protocols AES, TLS, IPsec have long been used by providers. At the same time, the cases of data leakages among large corporation still take place. Data Security.
github.com Their core repos consist of SparseML: a toolkit that includes APIs, CLIs, scripts and libraries that apply optimization algorithms such as pruning and quantization to any neural network. Neural Magic Neural Magic has 6 repositories available. Follow their code on GitHub. SparseZoo: a model repo for sparse models. Connected Papers
EBS volumes are particularly well-suited for use as the primary storage for file systems, databases, or for any applications that require fine granular updates and access to raw, unformatted, block-level storage. We recommend Amazon EBS for data that must be quickly accessible and requires long-term persistence.
In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN. This is accomplished by breaking the problem into independent parts so that each processing element can complete its part of the workload algorithm simultaneously.
Sometimes it’s a story of creating a superalgorithm that encapsulates decades of algorithmic development. And in a similar vein, we can expect LLMs to be useful in making connections to external databases, functions, etc. In addition, a new algorithm in Version 14.0 had 554 built-in functions; in Version 14.0 there are 6602.
Use algorithm to determine closeness/similarity of points. Like traditional database index, vector index organizes the vectors into a data structure and makes it possible to navigate through the vectors and find the ones that are closest in terms of semantic similarity. This is embedding/vector/vector embedding for this article.
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system. Andrew Gordon Wilson before joining Amazon in 2018.
These include biometric categorization systems based on sensitive characteristics, untargeted scraping of facial images from the internet or CCTV footage to create facial recognition databases, emotion recognition in the workplace and schools, and predictive policing. ” asks Dalen.
The foundations for today’s generative language applications were elaborated in the 1990s ( Hochreiter , Schmidhuber ), and the whole field took off around 2018 ( Radford , Devlin , et al.). Generative AI models usually have millions of neurons and billions of synapses (aka „ parameters “).
With the application of natural language processing (NLP) and machine learning algorithms, AI systems can understand and translate spoken language into written notes. Utilizing its CognitiveML engine, Iodine Software implements advanced machine learning across various use-case scenarios within a database of patient admissions.
Health startups and tech companies aiming to integrate AI technologies account for a large proportion of AI-specific investments, accounting for up to $2 billion in 2018 ( Figure 1 ). For example, the Institute of Cancer Research cancer database combines genetic and clinical data from patients with information from scientific research.
For example, supporting equitable student persistence in computing research through our Computer Science Research Mentorship Program , where Googlers have mentored over one thousand students since 2018 — 86% of whom identify as part of a historically marginalized group. sequence protein database with annotations. MGnify proteins A 2.4B-sequence
Here are a few reasons why an agent needs tools: Access to external resources: Tools allow an agent to access and retrieve information from external sources, such as databases, APIs, or web scraping. This includes cleaning and transforming data, performing calculations, or applying machine learning algorithms.
Emergence Google coined the term federated learning (FL) during the Cambridge Analytical scandal of 2018. Model aggregation occurs when the central ML model receives updates from the IoT devices to improve it (one common approach is using the federated averaging algorithm ). The IoT devices send model updates to the central server.
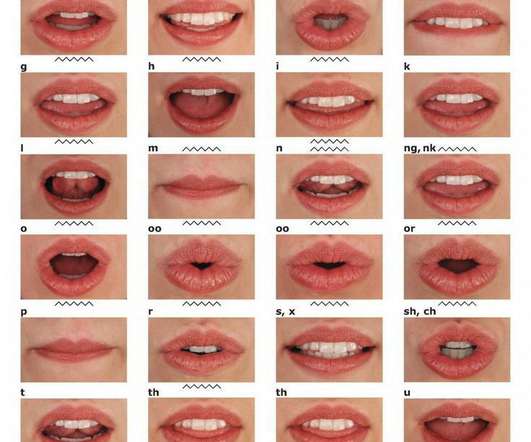
17] “ LipNet ” introduces the first approach for an end-to-end lip reading algorithm at sentence level. 27] LipNet also makes use of an additional algorithm typically used in speech recognition systems — a Connectionist Temporal Classification (CTC) output. Thus the algorithm is alignment-free. Vive Differentiable Programming!
al, 2015) is a twist on the word2vec family of algorithms that lets you learn more interesting word vectors. s2v_reddit_md") seed_keys = [s2v.get_best_sense(seed) for seed in seeds] most_similar = s2v.most_similar(seed_keys, n=10) As we annotate, the answers are sent back to the server and stored in the database.
Then we subsequently try to run audio fingerprinting type algorithms on top of it so that we can actually identify specifically who those people are if we’ve seen them in the past. We need to do that, but we don’t really know what those topics are, so we use some algorithms. We call it our “format stage.”
According to Investopedia.com, blockchains are databases that are irreversible and decentralized which makes it a great tool for business and finance in a new technological era. As mentioned above, blockchains are essentially databases, but not your typical database. Bitcoin has been very important for many businesses.
Advance algorithms and analytic approaches for early prediction of AD/ADRD, with an emphasis on explainability of predictions. Top solvers from Phase 2 demonstrate algorithmic approaches on diverse datasets and share their results at an innovation event. Phase 2 [Build IT!] Phase 3 [Put IT All Together!]
But it turns out that beyond the lemma we already discussed there are only three (highlighted here) that appear in the proof we are studying here: And indeed the main algorithmic challenge of theorem proving is to figure out which lemmas to generate in order to get a path to the theorem ones trying to prove. will tend to do better.
And so were in a position to compare the results of human effort (aided, in many cases, by systematic search) with what we can automatically do by the algorithmic process of adaptive evolution. Butas was actually already realized in the mid-1990sits still possible to use algorithmic methods to fill in pieces of patterns.
In 2018, I wrote an article discussing the creation of the internet — whether intentional or accidental, I’ll leave that debate aside — for the purpose of establishing the foundation for artificial intelligence ( click here to read ). is not rocket science and nothing more than an algorithm. Consequently, A.I.
Each layer can then be tested independently. // JavaScript const input = infrastructure.readData(); const output = logic.processInput(input); infrastructure.writeData(output); This simple algorithm can handle sophisticated needs if put into a stateful loop. For databases, access a real database. It’s easy to make a mistake.
Prior to the current hype cycle, generative machine learning tools like the “Smart Compose” feature rolled out by Google in 2018 weren’t heralded as a paradigm shift, despite being harbingers of today’s text generating services.
Core4ce Cyberscape: unmasking cyber threats Since 2018, Core4ce’s team of data scientists, engineers, and cyber experts has helped the US federal government solve complex challenges with data. That’s exactly what Core4ce’s Cyberscape platform does. Bridging data silos Once we have our seed nodes on the chart, we start enriching them.
In 2018, GlaxoSmithKline (GSK) piloted a new vaccine that may outmatch the BCG vaccine in treating pulmonary TB in adults. Researchers in 2018 tested out another TB vaccine, called H4:IC31 , against two control groups — a placebo arm and an arm receiving a BCG booster. OK, Computer. tuberculosis. coli bacteria from growing.
Large language models (LLMs) can help uncover insights from structured data such as a relational database management system (RDBMS) by generating complex SQL queries from natural language questions, making data analysis accessible to users of all skill levels and empowering organizations to make data-driven decisions faster than ever before.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content