This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. These algorithms use existing data like text, images, and audio to generate content that looks like it comes from the real world.
Naturallanguageprocessing: Google Duplex applies advanced naturallanguage understanding and generation techniques to facilitate interactive conversations that feel human-like. Technological foundation of Google Duplex To achieve its impressive functionality, Google Duplex leverages several core technologies.
However, with the introduction of Deep Learning in 2018, predictive analytics in engineering underwent a transformative revolution. It replaces complex algorithms with neural networks, streamlining and accelerating the predictive process. Techniques Uses statistical models, machine learning algorithms, and data mining.
Black box algorithms such as xgboost emerged as the preferred solution for a majority of classification and regression problems. Later, Python gained momentum and surpassed all programming languages, including Java, in popularity around 2018–19. Welcome to PyTorch Tutorials – PyTorch Tutorials 2.2.0+cu121
Kingma is best known for co-developing several groundbreaking techniques in AI, including the Adam optimizer , a widely-used optimization algorithm in deep learning, and Variational Autoencoders (VAE) , a type of generative model that enables unsupervised learning and has applications in image generation and other AI tasks.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (NaturalLanguageProcessing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
— Ilya Sutskever, chief scientist of OpenAI WE CAN CONNECT ON :| LINKEDIN | TWITTER | MEDIUM | SUBSTACK | In recent years, there has been a great deal of buzz surrounding large language models, or LLMs for short. In the 1980s and 1990s, the field of naturallanguageprocessing (NLP) began to emerge as a distinct area of research within AI.
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
In the first part of the series, we talked about how Transformer ended the sequence-to-sequence modeling era of NaturalLanguageProcessing and understanding. So, the authors have used a two-stage process, following what we do as humans. And we will also look at certain developments along the path.
A Mongolian pharmaceutical company engaged in a pilot study in 2018 to detect fake drugs, an initiative with the potential to save hundreds of thousands of lives. Laypeople surfing the internet, subject to targeted content based on algorithms, must train themselves to question every byte of data they interact with.
Predictive analytics: Predictive analytics leverages historical data and statistical algorithms to make predictions about future events or trends. It’s particularly valuable for forecasting demand, identifying potential risks, and optimizing processes. Non-compliance can result in hefty fines.
AI and Climate change Mining for AI: Natural Resource Extraction To understand what AI is made from, we need to leave Silicon Valley and go to the place where the stuff for the AI industry is made. China’s data center industry gets 73% of its power from coal, emitting roughly 99 million tons of CO2 in 2018 [4].
You might have received a lengthy email from your coworker, and you could simply press on the ‘Got it’ response suggested by Google’s AI algorithm to compose your reply. Earlier in 2019, the AI development company OpenAI developed a text-writing algorithm named GPT-2 that could use machine learning to generate content.
BERT is an open source machine learning framework for naturallanguageprocessing (NLP) that helps computers understand ambiguous language by using context from surrounding text. based search algorithms, enhancing the understanding of roughly 10% of English search queries.
With the application of naturallanguageprocessing (NLP) and machine learning algorithms, AI systems can understand and translate spoken language into written notes. Founded in 2018, Mutuo Health Solutions has ushered in an inventive solution to the often cumbersome task of manual medical documentation.
Turing proposed the concept of a “universal machine,” capable of simulating any algorithmicprocess. The development of LISP by John McCarthy became the programming language of choice for AI research, enabling the creation of more sophisticated algorithms.
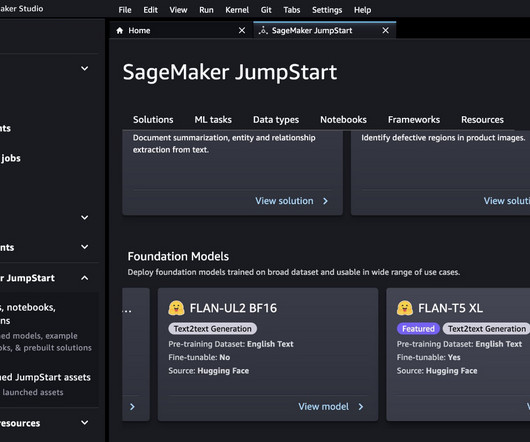
Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. From 2015–2018, he worked as a program director at the US NSF in charge of its big data program. He founded StylingAI Inc.,
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately? Algorithms can automatically detect and extract key items.
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). If you have a large dataset, the SageMaker KNN algorithm may provide you with an effective semantic search.
This retrieval can happen using different algorithms. Her research interests lie in NaturalLanguageProcessing, AI4Code and generative AI. He joined Amazon in 2016 as an Applied Scientist within SCOT organization and then later AWS AI Labs in 2018 working on Amazon Kendra.
His research focuses on applying naturallanguageprocessing techniques to extract information from unstructured clinical and medical texts, especially in low-resource settings. I love participating in various competitions involving deep learning, especially tasks involving naturallanguageprocessing or LLMs.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., Understanding the robustness of image segmentation algorithms to adversarial attacks is critical for ensuring their reliability and security in practical applications.
By using our mathematical notation, the entire training process of the autoencoder can be written as follows: Figure 2 demonstrates the basic architecture of an autoencoder: Figure 2: Architecture of Autoencoder (inspired by Hubens, “Deep Inside: Autoencoders,” Towards Data Science , 2018 ).
This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy. It is based on GPT and uses machine learning algorithms to generate code suggestions as developers write.
At its core, Meta-Learning equips algorithms with the aptitude to quickly grasp new tasks and domains based on past experiences, paving the way for unparalleled problem-solving skills and generalization abilities. MAML trains a model's initial parameters to fine-tune rapidly for new tasks with just a few examples.
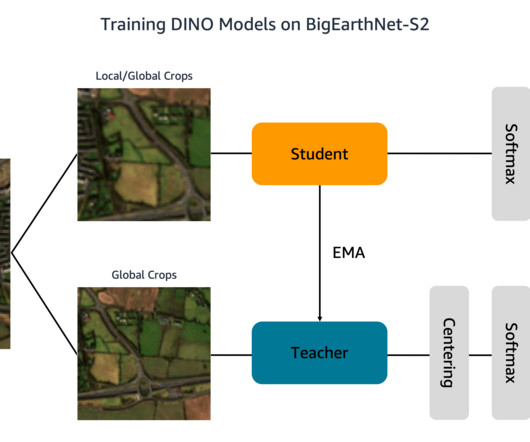
Our solution is based on the DINO algorithm and uses the SageMaker distributed data parallel library (SMDDP) to split the data over multiple GPU instances. The images document the land cover, or physical surface features, of ten European countries between June 2017 and May 2018. tif" --include "_B03.tif" tif" --include "_B04.tif"
Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data. A foundation model is built on a neural network model architecture to process information much like the human brain does. An open-source model, Google created BERT in 2018.
Large language models In recent years, language models have seen a huge surge in size and popularity. In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. Q: Can I stop an Amazon SageMaker Autopilot job manually?
According to a report by Statista, the global data sphere is expected to reach 180 zettabytes by 2025 , a significant increase from 33 zettabytes in 2018. For example, financial institutions utilise high-frequency trading algorithms that analyse market data in milliseconds to make investment decisions.
According to a report by Statista, the global data sphere is expected to reach 180 zettabytes by 2025 , a significant increase from 33 zettabytes in 2018. For example, financial institutions utilise high-frequency trading algorithms that analyse market data in milliseconds to make investment decisions.
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. We design an algorithm that automatically identifies the ambiguity between these two classes as the overlapping region of the clusters. Each season consists of around 17,000 plays. probability.
This article is part of the Academic Alibaba series and is taken from the paper entitled “Learning Chinese Word Embeddings with Stroke n-gram Information” by Shaosheng Cao, Wei Lu, Jun Zhou, and Xiaolong Li, accepted by the 2018 Conference of the Association for the Advancement of Artificial Intelligence. The full paper can be read here.
Amazon EBS is well suited to both database-style applications that rely on random reads and writes, and to throughput-intensive applications that perform long, continuous reads and writes. """, """ Amazon Comprehend uses naturallanguageprocessing (NLP) to extract insights about the content of documents.
Then we subsequently try to run audio fingerprinting type algorithms on top of it so that we can actually identify specifically who those people are if we’ve seen them in the past. We need to do that, but we don’t really know what those topics are, so we use some algorithms. We call it our “format stage.” Not all, but some.
Recent Intersections Between Computer Vision and NaturalLanguageProcessing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and NaturalLanguageProcessing (NLP). Image Captioning with Semantic Attention (You et al.,
For example, supporting equitable student persistence in computing research through our Computer Science Research Mentorship Program , where Googlers have mentored over one thousand students since 2018 — 86% of whom identify as part of a historically marginalized group.
The recent history of PBAs begins in 1999, when NVIDIA released its first product expressly marketed as a GPU, designed to accelerate computer graphics and image processing. In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN.
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system. Andrew Gordon Wilson before joining Amazon in 2018.
Health startups and tech companies aiming to integrate AI technologies account for a large proportion of AI-specific investments, accounting for up to $2 billion in 2018 ( Figure 1 ). Machine learning algorithms can also recognize patterns in DNA sequences and predict a patient’s probability of developing an illness.
But now, a computer can be taught to comprehend and process human language through NaturalLanguageProcessing (NLP), which was implemented, to make computers capable of understanding spoken and written language.
Modern naturallanguageprocessing has yielded tools to conduct these types of exploratory search, we just need to apply them to the data from valuable sources, such as ArXiv. In 2018, over 1000 papers have been released on ArXiv per month in the above areas. Every month except January.
of the spaCy NaturalLanguageProcessing library includes a huge number of features, improvements and bug fixes. spaCy is an open-source library for industrial-strength naturallanguageprocessing in Python. This is exactly what algorithms like word2vec, GloVe and FastText set out to solve.
al, 2015) is a twist on the word2vec family of algorithms that lets you learn more interesting word vectors. from_disk("/path/to/s2v_reddit_2015_md") nlp.add_pipe(s2v) doc = nlp("A sentence about naturallanguageprocessing.") text == "naturallanguageprocessing" freq = doc[3:6]._.s2v_freq
What the plot here on the X-axis is showing is just, from 2018 up to 2022, relative performance from the best system that we had because of a good benchmark like MLPerf and seeing what the improvement was with respect to “Moore’s Law” (because Moore’s law has been slowing now). And algorithms.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content