This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. These algorithms use existing data like text, images, and audio to generate content that looks like it comes from the real world.
AI practitioners choose an appropriate machine learning model or algorithm that aligns with the problem at hand. Common choices include neural networks (used in deep learning), decision trees, support vector machines, and more. Over time, the algorithm improves its accuracy and can make better predictions on new, unseen data.
Year and work published Generative Pre-trained Transformer (GPT) In 2018, OpenAI introduced GPT, which has shown, with the implementation of pre-training, transfer learning, and proper fine-tuning, transformers can achieve state-of-the-art performance. But, the question is, how did all these concepts come together?
Cleanlab is an open-source software library that helps make this process more efficient (via novel algorithms that automatically detect certain issues in data) and systematic (with better coverage to detect different types of issues). Data-centric AI instead asks how we can systematically engineer better data through algorithms/automation.
The quality of your training data in Machine Learning (ML) can make or break your entire project. This article explores real-world cases where poor-quality data led to model failures, and what we can learn from these experiences. Machine learningalgorithms rely heavily on the data they are trained on. The lesson here?
I generated unlabeled data for semi-supervisedlearning with Deberta-v3, then the Deberta-v3-large model was used to predict soft labels for the unlabeled data. The semi-supervisedlearning was repeated using the gemma2-9b model as the soft labeling model. Then we leveraged the benefits of NLP algorithms (e.g.,
Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data. They can also perform self-supervisedlearning to generalize and apply their knowledge to new tasks. An open-source model, Google created BERT in 2018.
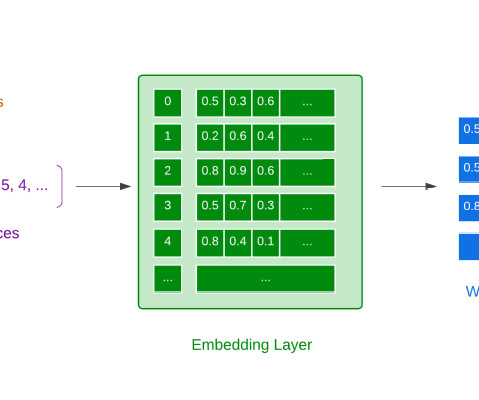
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. What is self-supervisedlearning? Self-supervisedlearning is a kind of machine learning that creates labels directly from the input data. Find out in the guide below.
One example is the Pairwise Inner Product (PIP) loss, a metric designed to measure the dissimilarity between embeddings using their unitary invariance (Yin and Shen, 2018). Yin and Shen (2018) accompany their research with a code implementation on GitHub here. Fortunately, there is; use an embedding loss. Equation 2.3.1. and Auli, M.,
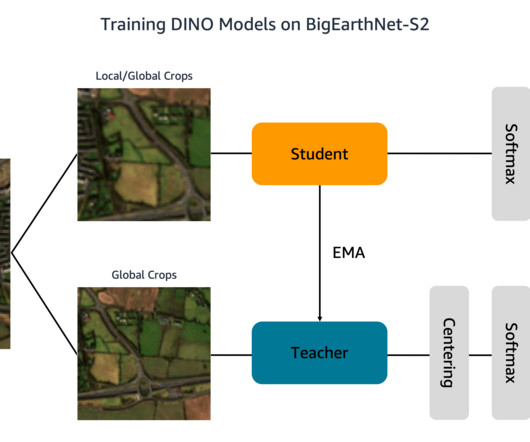
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervisedlearning (SSL). The types of land cover in each image, such as pastures or forests, are annotated according to 19 labels.
Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. They were followed in 2017 by VQ-VAE, proposed in “ Neural Discrete Representation Learning ”, a vector-quantized variational autoencoder. Let’s get started!
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: Support Vector Machine , S upport Vectors and Linearly vs. Non-linearly Separable Data. Support Vector Machine Support Vector Machine ( SVM ) is a supervisedlearningalgorithm used for classification and regression analysis.
As per the recent report by Nasscom and Zynga, the number of data science jobs in India is set to grow from 2,720 in 2018 to 16,500 by 2025. Top 5 Colleges to Learn Data Science (Online Platforms) 1. The amount increases with experience and varies from industry to industry.
Technology and methodology DeepMind’s approach revolves around sophisticated machine learning methods that enable AI to interact with its environment and learn from experience. Input and learning process To begin learning, DeepMind systems take in raw data, often in the form of pixel information.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content