This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Neural Magic is a startup company that focuses on developing technology that enables deeplearning models to run on commodity CPUs rather than specialized hardware like GPUs. The company was founded in 2018 by Alexander Matveev, a former researcher at MIT, and Nir Shavit, a professor of computer science at MIT.
In the old days, transfer learning was a concept mostly used in deeplearning. However, in 2018, the “Universal Language Model Fine-tuning for Text Classification” paper changed the entire landscape of Natural Language Processing (NLP). This paper explored models using fine-tuning and transfer learning.
Introduction In 2018, when we were contemplating whether AI would take over our jobs or not, OpenAI put us on the edge of believing that. Our way of working has completely changed after the inception of OpenAI’s ChatGPT in 2022. But is it a threat or a boon?
DataHack Summit 2019 Bringing Together Futurists to Achieve Super Intelligence DataHack Summit 2018 was a grand success with more than 1,000 attendees from various. The post Announcing DataHack Summit 2019 – The Biggest Artificial Intelligence and Machine Learning Conference Yet appeared first on Analytics Vidhya.
A visual representation of discriminative AI – Source: Analytics Vidhya Discriminative modeling, often linked with supervised learning, works on categorizing existing data. This breakthrough has profound implications for drug development, as understanding protein structures can aid in designing more effective therapeutics.
We’ll dive into the core concepts of AI, with a special focus on Machine Learning and DeepLearning, highlighting their essential distinctions. However, with the introduction of DeepLearning in 2018, predictive analytics in engineering underwent a transformative revolution.
The tweet linked to a paper from 2018, hinting at the foundational research behind these now-commercialized ideas. Back in 2018, recent CDS PhD grad Katrina Drozdov (née Evtimova), Cho, and their colleagues published a paper at ICLR called “ Emergent Communication in a Multi-Modal, Multi-Step Referential Game.”
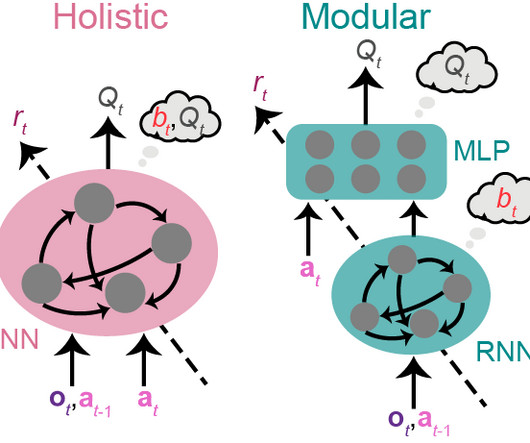
2018 ) to enhance training (see Materials and Methods in Zhang et al., It then outputs the estimated (Q_t) for this action, trained through the temporal-difference error (TD error) after receiving the reward (r_t) ((|r_t+gamma Q_{t+1}-Q_{t}|), where (gamma) denotes the temporal discount factor).
Deeplearning is now being used to translate between languages, predict how proteins fold , analyze medical scans , and play games as complex as Go , to name just a few applications of a technique that is now becoming pervasive. Although deeplearning's rise to fame is relatively recent, its origins are not.
Deeplearning And NLP DeepLearning and Natural Language Processing (NLP) are like best friends in the world of computers and language. DeepLearning is when computers use their brains, called neural networks, to learn lots of things from a ton of information. I was developed by OpenAI in 2018.
Emerging as a key player in deeplearning (2010s) The decade was marked by focusing on deeplearning and navigating the potential of AI. Introduction of cuDNN Library: In 2014, the company launched its cuDNN (CUDA Deep Neural Network) Library. It provided optimized codes for deeplearning models.
Timeline of key milestones Launch of Siri with the iPhone 4S in 2011 Expansion to iPads and Macs in 2013 Introduction of Siri to Apple TV and the HomePod in 2018 The anticipated Apple Intelligence update in 2024, enhancing existing features How does Siri work?
Luckily, a few of them are willing to share data science, machine learning and deeplearning materials online for everyone. Here is just I small list I have come across lately.
In this article, we embark on a journey to explore the transformative potential of deeplearning in revolutionizing recommender systems. However, deeplearning has opened new horizons, allowing recommendation engines to unravel intricate patterns, uncover latent preferences, and provide accurate suggestions at scale.
Deeplearning — a software model that relies on billions of neurons and trillions of connections — requires immense computational power. In 2018, NVIDIA debuted GeForce RTX (20 Series) with RT Cores and Tensor Cores, designed specifically for real-time ray tracing and AI workloads.
Picture created with Dall-E-2 Yoshua Bengio, Geoffrey Hinton, and Yann LeCun, three computer scientists and artificial intelligence (AI) researchers, were jointly awarded the 2018 Turing Prize for their contributions to deeplearning, a subfield of AI.
Health startups and tech companies aiming to integrate AI technologies account for a large proportion of AI-specific investments, accounting for up to $2 billion in 2018 ( Figure 1 ). This blog will cover the benefits, applications, challenges, and tradeoffs of using deeplearning in healthcare.
cum laude in machine learning from the University of Amsterdam in 2017. His academic work, particularly in deeplearning and generative models, has had a profound impact on the AI community. However, in 2018, he transitioned to being a part-time angel investor and advisor to AI startups, and later rejoined Google Brain.
Yes, large language models (LLMs) hallucinate , a concept popularized by Google AI researchers in 2018. Hallucinations May Be Inherent to Large Language Models But Yann LeCun , a pioneer in deeplearning and the self-supervised learning used in large language models, believes there is a more fundamental flaw that leads to hallucinations.
Later, Python gained momentum and surpassed all programming languages, including Java, in popularity around 2018–19. The advent of more powerful personal computers paved the way for the gradual acceptance of deeplearning-based methods. CS6910/CS7015: DeepLearning Mitesh M. Khapra Homepage www.cse.iitm.ac.in
Dann etwa im Jahr 2018 flachte der Hype um Big Data wieder ab, die Euphorie änderte sich in eine Ernüchterung, zumindest für den deutschen Mittelstand. GPT-3 ist jedoch noch komplizierter, basiert nicht nur auf Supervised DeepLearning , sondern auch auf Reinforcement Learning.
In order to learn the nuances of language and to respond coherently and pertinently, deeplearning algorithms are used along with a large amount of data. A prompt is given to GPT-3 and it produces very accurate human-like text output based on deeplearning. AI chatbot ChatGPT is based on GPT-3.5,
By using our mathematical notation, the entire training process of the autoencoder can be written as follows: Figure 2 demonstrates the basic architecture of an autoencoder: Figure 2: Architecture of Autoencoder (inspired by Hubens, “Deep Inside: Autoencoders,” Towards Data Science , 2018 ). Or requires a degree in computer science?
Co-inventing AlexNet with Krizhevsky and Hinton, he laid the groundwork for modern deeplearning. Keynote speeches at Nvidia Ntech 2018 and AI Frontiers Conference 2018 cement his status as a thought leader. His thirst for knowledge took him to the University of Toronto in Canada, where he clinched his Ph.D.
Some of the methods used for scene interpretation include Convolutional Neural Networks (CNNs) , a deeplearning-based methodology, and more conventional computer vision-based techniques like SIFT and SURF. A combination of simulated and real-world data was used to train the system, enabling it to generalize to new objects and tasks.
“A lot happens to these interpretability artifacts during training,” said Chen, who believes that by only focusing on the end result, we might be missing out on understanding the entire journey of the model’s learning. The paper is a case study of syntax acquisition in BERT (Bidirectional Encoder Representations from Transformers).
It wasn’t until the development of deeplearning algorithms in the 2000s and 2010s that LLMs truly began to take shape. Deeplearning algorithms are designed to mimic the structure and function of the human brain, allowing them to process vast amounts of data and learn from that data over time.
Since 2018, using state-of-the-art proprietary and open source large language models (LLMs), our flagship product— Rad AI Impressions — has significantly reduced the time radiologists spend dictating reports, by generating Impression sections. This post is co-written with Ken Kao and Hasan Ali Demirci from Rad AI.
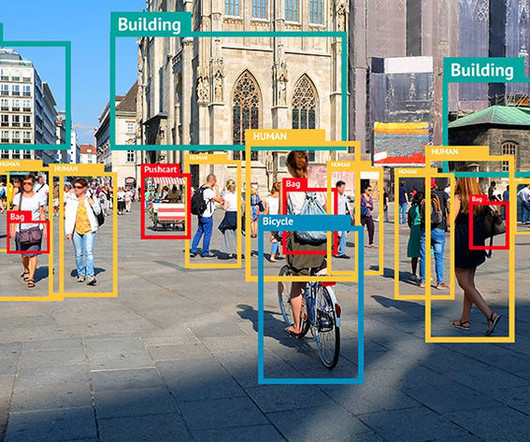
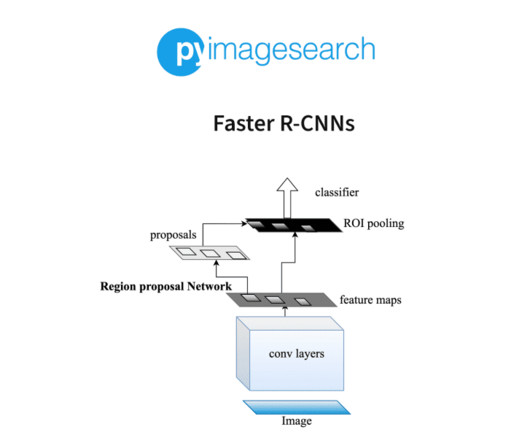
Home Table of Contents Faster R-CNNs Object Detection and DeepLearning Measuring Object Detector Performance From Where Do the Ground-Truth Examples Come? One of the most popular deeplearning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al.
Grand Teton is designed with compute capacity to support the demands of memory-bandwidth-bound workloads, such as Meta’s deeplearning recommendation models ( DLRMs ), as well as compute-bound workloads like content understanding.
He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deeplearning on tabular data, and robust analysis of non-parametric space-time clustering. Yida Wang is a principal scientist in the AWS AI team of Amazon. He founded StylingAI Inc.,
Minor changes in the input data that are very apparent to human intelligence are not so for deeplearning models. Deeplearning is essentially matrix multiplication, which means even small perturbations in the coefficients can cause a significant change in the output.
In particular, min-max optimisation is curcial for GANs [2], statistics, online learning [6], deeplearning, and distributed computing [7]. Vladu, “Towards deeplearning models resistant to adversarial attacks,” arXivpreprint arXiv:1706.06083, 2017.[5] Arjovsky, S. Chintala, and L. 214–223, 2017.[4] Makelov, L.
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football.
yml file from the AWS DeepLearning Containers GitHub repository, illustrating how the model synthesizes information across an entire repository. Codebase analysis with Llama 4 Using Llama 4 Scouts industry-leading context window, this section showcases its ability to deeply analyze expansive codebases. billion to a projected $574.78
China’s data center industry gets 73% of its power from coal, emitting roughly 99 million tons of CO2 in 2018 [4]. In 2018, OpenAI released an analysis showing that since 2012, the amount of computing used in the largest AI training runs has been increasing exponentially, with a doubling time of 3–4 months [8].
Year and work published Generative Pre-trained Transformer (GPT) In 2018, OpenAI introduced GPT, which has shown, with the implementation of pre-training, transfer learning, and proper fine-tuning, transformers can achieve state-of-the-art performance.
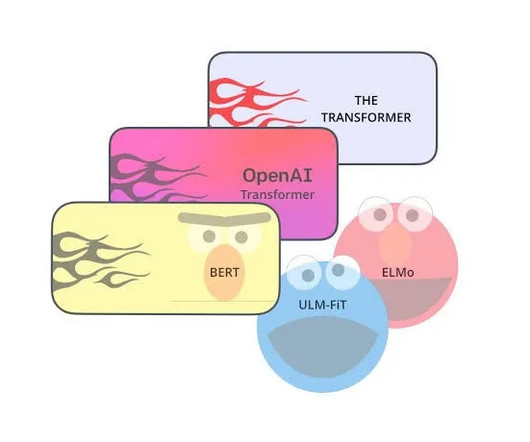
DeepLearning (Late 2000s — early 2010s) With the evolution of needing to solve more complex and non-linear tasks, The human understanding of how to model for machine learning evolved. 2017) “ BERT: Pre-training of deep bidirectional transformers for language understanding ” by Devlin et al.
Introduced in 2018, BERT has been a topic of interest for many, with many articles and YouTube videos attempting to break it down. Want to Learn Quantization in The Large Language Model? By Milan Tamang Quantization is a method of compressing a larger size model (LLM or any deeplearning model) to a smaller size.
Recent studies have demonstrated that deeplearning-based image segmentation algorithms are vulnerable to adversarial attacks, where carefully crafted perturbations to the input image can cause significant misclassifications (Xie et al., 2018; Sitawarin et al., 2018; Papernot et al., 2018; Papernot et al.,
When it comes to deeplearning models, that are often used for more complex problems and sequential data, Long Short-Term Memory (LSTM) networks or Transformers are applied. For more information on how to calculate the marginal distribution, see Zhao et al. References Zhao, K., Mahboobi, S. H., & Bagheri, S.
The foundations for today’s generative language applications were elaborated in the 1990s ( Hochreiter , Schmidhuber ), and the whole field took off around 2018 ( Radford , Devlin , et al.). Deeplearning neural network. In the code, the complete deeplearning network is represented as a matrix of weights.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























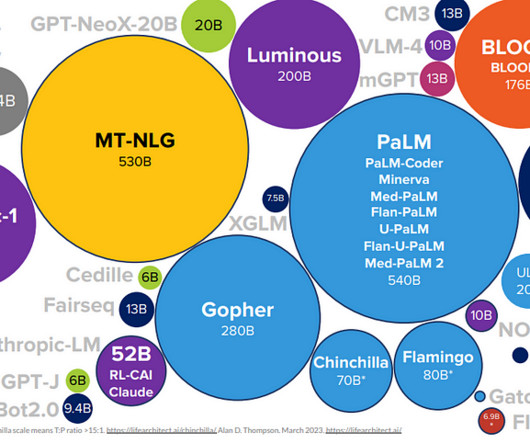


















Let's personalize your content