This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Welcome to the world of Large Language Models (LLM). In the old days, transfer learning was a concept mostly used in deeplearning. However, in 2018, the “Universal Language Model Fine-tuning for Text Classification” paper changed the entire landscape of NaturalLanguageProcessing (NLP).
Transformer models are a type of deeplearning model that are used for naturallanguageprocessing (NLP) tasks. They are able to learn long-range dependencies between words in a sentence, which makes them very powerful for tasks such as machine translation, text summarization, and question answering.
Transformer models are a type of deeplearning model that are used for naturallanguageprocessing (NLP) tasks. They are able to learn long-range dependencies between words in a sentence, which makes them very powerful for tasks such as machine translation, text summarization, and question answering.
A visual representation of discriminative AI – Source: Analytics Vidhya Discriminative modeling, often linked with supervised learning, works on categorizing existing data. This breakthrough has profound implications for drug development, as understanding protein structures can aid in designing more effective therapeutics.
Timeline of key milestones Launch of Siri with the iPhone 4S in 2011 Expansion to iPads and Macs in 2013 Introduction of Siri to Apple TV and the HomePod in 2018 The anticipated Apple Intelligence update in 2024, enhancing existing features How does Siri work?
Deeplearning And NLP DeepLearning and NaturalLanguageProcessing (NLP) are like best friends in the world of computers and language. DeepLearning is when computers use their brains, called neural networks, to learn lots of things from a ton of information.
We’ll dive into the core concepts of AI, with a special focus on Machine Learning and DeepLearning, highlighting their essential distinctions. However, with the introduction of DeepLearning in 2018, predictive analytics in engineering underwent a transformative revolution.
Later, Python gained momentum and surpassed all programming languages, including Java, in popularity around 2018–19. The advent of more powerful personal computers paved the way for the gradual acceptance of deeplearning-based methods. CS6910/CS7015: DeepLearning Mitesh M.
Picture created with Dall-E-2 Yoshua Bengio, Geoffrey Hinton, and Yann LeCun, three computer scientists and artificial intelligence (AI) researchers, were jointly awarded the 2018 Turing Prize for their contributions to deeplearning, a subfield of AI.
cum laude in machine learning from the University of Amsterdam in 2017. His academic work, particularly in deeplearning and generative models, has had a profound impact on the AI community. However, in 2018, he transitioned to being a part-time angel investor and advisor to AI startups, and later rejoined Google Brain.
However, these early systems were limited in their ability to handle complex language structures and nuances, and they quickly fell out of favor. In the 1980s and 1990s, the field of naturallanguageprocessing (NLP) began to emerge as a distinct area of research within AI.
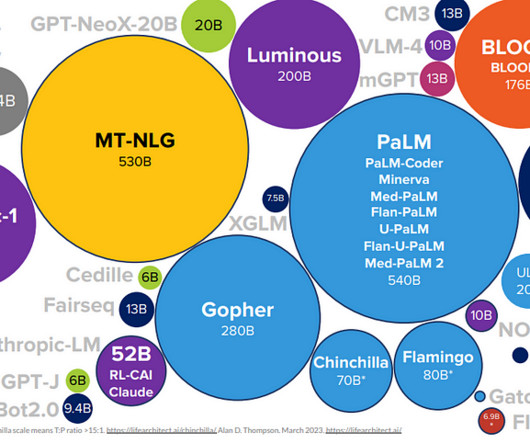
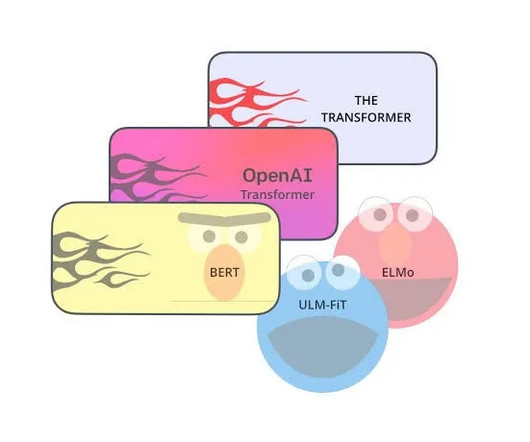
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (NaturalLanguageProcessing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
Health startups and tech companies aiming to integrate AI technologies account for a large proportion of AI-specific investments, accounting for up to $2 billion in 2018 ( Figure 1 ). This blog will cover the benefits, applications, challenges, and tradeoffs of using deeplearning in healthcare.
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
In the first part of the series, we talked about how Transformer ended the sequence-to-sequence modeling era of NaturalLanguageProcessing and understanding. The authors introduced the idea of transfer learning in the naturallanguageprocessing, understanding, and inference world.
By using our mathematical notation, the entire training process of the autoencoder can be written as follows: Figure 2 demonstrates the basic architecture of an autoencoder: Figure 2: Architecture of Autoencoder (inspired by Hubens, “Deep Inside: Autoencoders,” Towards Data Science , 2018 ). That’s not the case.
He focuses on developing scalable machine learning algorithms. His research interests are in the area of naturallanguageprocessing, explainable deeplearning on tabular data, and robust analysis of non-parametric space-time clustering. Yida Wang is a principal scientist in the AWS AI team of Amazon.
Building naturallanguageprocessing and computer vision models that run on the computational infrastructures of Amazon Web Services or Microsoft’s Azure is energy-intensive. China’s data center industry gets 73% of its power from coal, emitting roughly 99 million tons of CO2 in 2018 [4].
Tomorrow Sleep was launched in 2017 as a sleep system startup and ventured on to create online content in 2018. In order to achieve this, Grammarly’s technology combines machine learning with naturallanguageprocessing approaches. Tomorrow Sleep Achieved 10,000% Increase in Web Traffic.
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football.
His research focuses on applying naturallanguageprocessing techniques to extract information from unstructured clinical and medical texts, especially in low-resource settings. I love participating in various competitions involving deeplearning, especially tasks involving naturallanguageprocessing or LLMs.
” During this time, researchers made remarkable strides in naturallanguageprocessing, robotics, and expert systems. Notable achievements included the development of ELIZA, an early naturallanguageprocessing program created by Joseph Weizenbaum, which simulated human conversation.
You don’t need to have a PhD to understand the billion parameter language model GPT is a general-purpose naturallanguageprocessing model that revolutionized the landscape of AI. GPT-3 is a autoregressive language model created by OpenAI, released in 2020 . What is GPT-3?
Recent studies have demonstrated that deeplearning-based image segmentation algorithms are vulnerable to adversarial attacks, where carefully crafted perturbations to the input image can cause significant misclassifications (Xie et al., 2018; Sitawarin et al., 2018; Papernot et al., 2018; Papernot et al.,
Photo by Will Truettner on Unsplash NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 07.26.20 Last Updated on July 21, 2023 by Editorial Team Author(s): Ricky Costa Originally published on Towards AI. Primus The Liber Primus is unsolved to this day. It contains 3,654 question answer pairs.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately?
But now, a computer can be taught to comprehend and process human language through NaturalLanguageProcessing (NLP), which was implemented, to make computers capable of understanding spoken and written language. How RoBERTa Works It works by pre-training a deep neural network on a large corpus of text.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. A foundation model is built on a neural network model architecture to process information much like the human brain does.
RoBERTa: A Modified BERT Model for NLP — by Khushboo Kumari An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019.
The images document the land cover, or physical surface features, of ten European countries between June 2017 and May 2018. He is interested in solving business problems with the latest AI and deeplearning techniques including large language models, foundational imagery models, and generative AI.
Visual ChatGPT brings AI image generation to the popular chatbot Back to the present: GPT-4 is released The much-anticipated release of GPT-4 is now available to some Plus subscribers, featuring a new multimodal language model that accepts text, speech, images, and video as inputs and provides text-based answers.
For example, supporting equitable student persistence in computing research through our Computer Science Research Mentorship Program , where Googlers have mentored over one thousand students since 2018 — 86% of whom identify as part of a historically marginalized group.
Imagine an AI system that becomes proficient in many tasks through extensive training on each specific problem and a higher-order learningprocess that distills valuable insights from previous learning endeavors. Reptile is a meta-learning algorithm that falls under model-agnostic meta-learning approaches.
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). He focuses on developing scalable machine learning algorithms.
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. Haibo Ding is a senior applied scientist at Amazon Machine Learning Solutions Lab. He is broadly interested in DeepLearning and NaturalLanguageProcessing.
The recent history of PBAs begins in 1999, when NVIDIA released its first product expressly marketed as a GPU, designed to accelerate computer graphics and image processing. In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN.
Recent Intersections Between Computer Vision and NaturalLanguageProcessing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and NaturalLanguageProcessing (NLP). 2018) COCO: Common Objects in Context.
of the spaCy NaturalLanguageProcessing library includes a huge number of features, improvements and bug fixes. spaCy is an open-source library for industrial-strength naturallanguageprocessing in Python. Version 2.1 Prodigy is a fully scriptable annotation tool that complements spaCy extremely well.
In 2018, we did a piece of research where we tried to estimate the value of AI and machine learning across geographies, across use cases, and across sectors. One is compared to our first survey conducted in 2018, we see more enterprises investing in AI capability. We need data scientists familiar with deeplearning frameworks.
from_disk("/path/to/s2v_reddit_2015_md") nlp.add_pipe(s2v) doc = nlp("A sentence about naturallanguageprocessing.") text == "naturallanguageprocessing" freq = doc[3:6]._.s2v_freq For more examples and the full API documentation, see the GitHub repo. from sense2vec import Sense2Vec s2v = Sense2Vec().from_disk("/path/to/s2v_reddit_2015_md")
She started promoting herself on YouTube in 2018, and today she has over 750,000 subscribers. Her movies frequently include her friends and family, contributing to their comedic and approachable nature. In 2016, she began her career in social media by going live on YouNow.
Recent Intersections Between Computer Vision and NaturalLanguageProcessing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and NaturalLanguageProcessing (NLP). Thanks for reading!
The underlying DeepLearning Container (DLC) of the deployment is the Large Model Inference (LMI) NeuronX DLC. He focuses on developing scalable machine learning algorithms. Qing has in-depth knowledge on the infrastructure optimization and DeepLearning acceleration. He retired from EPFL in December 2016.nnIn
Large-scale deeplearning has recently produced revolutionary advances in a vast array of fields. is a startup dedicated to the mission of democratizing artificial intelligence technologies through algorithmic and software innovations that fundamentally change the economics of deeplearning. Founded in 2021, ThirdAI Corp.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content