This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his session, “ Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI ,” there! Anybody who has worked on a real-world ML project knows how messy data can be. Everybody knows you need to clean your data to get good ML performance. A common gripe I hear is: “Garbage in, garbage out.
Once you’re past prototyping and want to deliver the best system you can, supervisedlearning will often give you better efficiency, accuracy and reliability than in-context learning for non-generative tasks — tasks where there is a specific right answer that you want the model to find. That’s not a path to improvement.
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervisedlearning (SSL). Machine Learning Engineer at AWS. The following are a few example RGB images and their labels.
The quality of your training data in Machine Learning (ML) can make or break your entire project. Real-Life Examples of Poor Training Data in Machine Learning Amazon’s Hiring Algorithm Disaster In 2018, Amazon made headlines for developing an AI-powered hiring tool to screen job applicants. Sounds great, right?
Language Models Computer Vision Multimodal Models Generative Models Responsible AI* Algorithms ML & Computer Systems Robotics Health General Science & Quantum Community Engagement * Other articles in the series will be linked as they are released. language models, image classification models, or speech recognition models).
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. What is self-supervisedlearning? Self-supervisedlearning is a kind of machine learning that creates labels directly from the input data. Find out in the guide below.
One example is the Pairwise Inner Product (PIP) loss, a metric designed to measure the dissimilarity between embeddings using their unitary invariance (Yin and Shen, 2018). Yin and Shen (2018) accompany their research with a code implementation on GitHub here. Fortunately, there is; use an embedding loss. Equation 2.3.1. and Auli, M.,
As per the recent report by Nasscom and Zynga, the number of data science jobs in India is set to grow from 2,720 in 2018 to 16,500 by 2025. Top 5 Colleges to Learn Data Science (Online Platforms) 1. also offers free classes on Machine Learning that cover the core concepts of ML. In addition, Pickl.AI
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: Support Vector Machine , S upport Vectors and Linearly vs. Non-linearly Separable Data. Support Vector Machine Support Vector Machine ( SVM ) is a supervisedlearning algorithm used for classification and regression analysis.
AWS ProServe solved this use case through a joint effort between the Generative AI Innovation Center (GAIIC) and the ProServe ML Delivery Team (MLDT). However, LLMs are not a new technology in the ML space. The new ML workflow now starts with a pre-trained model dubbed a foundation model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



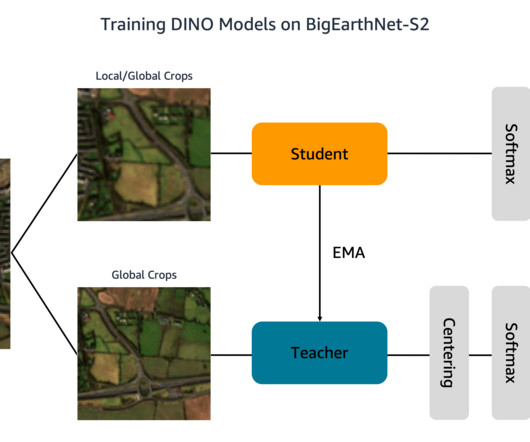



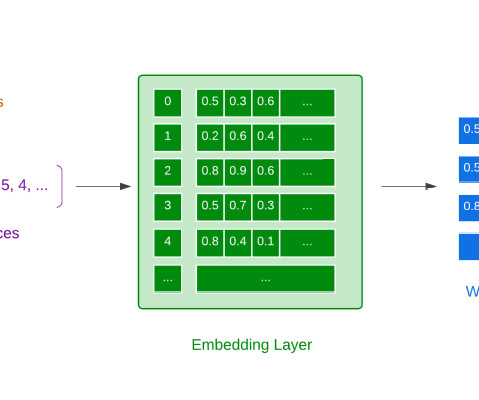


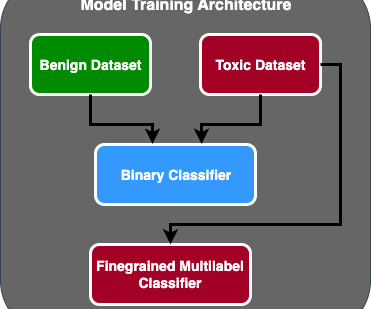






Let's personalize your content