This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using the “Top Spotify songs from 2010-2019” dataset on Kaggle ( [link] ), we read it into a Python – Pandas Data Frame. This is a default index created by python for this dataset, while considering the first column present in the csv file as an “unnamed” column. Similarly, we can set index columns according to our requirements.
(If you would prefer to watch a 30 minute talk on this same content, you can watch my Python US 2018 keynote [[link] Who am I? [1] 1] To start, I want to provide my bonafides so you know I'm not some crank spouting some armchair
Source: Canva|Arxiv Introduction In 2018 GoogleAI researchers developed Bidirectional Encoder Representations from Transformers (BERT) for various NLP tasks. This article was published as a part of the Data Science Blogathon.
Source: Canva Introduction In 2018 the researchers of OpenAI presented a framework for achieving strong natural language understanding (NLU) with a single task-agnostic model through generative pre-training and discriminative fine-tuning. This article was published as a part of the Data Science Blogathon.
Source: Canva Introduction In 2018, Google AI researchers came up with BERT, which revolutionized the NLP domain. This article was published as a part of the Data Science Blogathon.
In the year 2018, Google launched cloud AutoML which gained a lot of interest and is one of the most significant tools in the field of Machine Learning and Artificial Intelligence. Introduction AutoML is also known as Automatic Machine Learning.
However, in 2018, the “Universal Language Model Fine-tuning for Text Classification” paper changed the entire landscape of Natural Language Processing (NLP). Introduction Welcome to the world of Large Language Models (LLM). In the old days, transfer learning was a concept mostly used in deep learning.
Preparations are well underway for the 2018 edition of Data Natives– the data driven conference of the future, hosted in Dataconomy’s hometown of Berlin. The post First Speakers Announced for Data Natives 2018, The Tech Conference of the Future appeared first on Dataconomy.
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. For 2018, because AWS DeepRacer had just been unveiled, re:Invent attendees could compete in person at the MGM Grand using pre-trained models.
Summary: Reversing a list in Python is easy using slicing, reversed(), loops, or list comprehension. Master Python and essential data science skills with Pickl.AIs free course to enhance your career in data science. Introduction Python is one of the most popular programming languages today. What is Slicing in Python?
Works today Full Fortran 2018 parser LFortran can parse any Fortran 2018 syntax to AST (Abstract Syntax Tree) and format it back as Fortran source code (lfortran fmt). Feature Highlights LFortran is in development, there are features that work today, and there are features that are being implemented.
Go Machine Learning Projects (2018) – this book uses gonum and gorgonia in the examples Machine Learning with Go (2017). Stackoverflow “Go really can be that much faster than python” Reasons to use Golang for Data Science. Golang Data Science Books. There have even been a couple books written about the topic.
These are the writeups of the problems I solved over the weekend for the NeverLAN CTF 2018. File So, we write a simple python script to do it. Scripting Challenges 1. Basic Math We are given a file with some numbers which we had to sum. This gives the flag — 49562942146280612 2.
Later, Python gained momentum and surpassed all programming languages, including Java, in popularity around 2018–19. Major language models like GPT-3 and BERT often come with Python APIs, making it easy to integrate them into various applications. Expand your skillset by… courses.analyticsvidhya.com 2.
MIT Deep Learning – Lecture notes, slides and guest talks about deep learning and self driving cars Introduction to Artificial Intelligence from UC Berkeley – lecture notes, slides, homework from the Fall 2018 course Deep Learning Course from University of Paris-Saclay – lecture notes and Python code Stanford Machine Learning – (..)
Discover Llama 4 models in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the Amazon SageMaker Python SDK. Alternatively, you can use the SageMaker Python SDK to programmatically access and use SageMaker JumpStart models. billion to a projected $574.78
Nine out of ten use Python or R and about 80% of the cohort holds at least a Master’s degree. And that’s remained a consistent trend over the past two years (40% in 2018 and 43% in 2019). 74% of the cohort uses Python, 56% are proficient in R, and 51% have good command of SQL. Coding Languages.
The agent also utilizes Python in Lambda and the Amazon SageMaker SDK for computations and quantitative modeling. Python Calculation Tool – To use for mathematical calculations. One way to convert a Python-based function to an LLM tool is to use the BaseTool wrapper. A Python REPL tool allows the agent to run Python code.
A collection of Python scripts, including the ones originally used to crawl the data, and to perform experiments. 2024) arXiv:2404.18984 Acknowledgments: This work is supported by : the European Union – Horizon 2020 Program under the scheme “INFRAIA-01-2018-2019 – Integrating Activities for Advanced Communities”, Grant Agreement n.871042,
Gilead Sciences provided a rich, real-world dataset that contains information about demographics, diagnosis and treatment options, and insurance provided to patients who were diagnosed with breast cancer from 2015–2018. The dataset originated from Health Verity, one of the largest healthcare data ecosystems in the US.
Their infrastructure is built on top of FastAPI and supports Python, Go and Ruby languages. which features a nice tutorial for you to get familiar with their library: Contextualized Topic Modeling with Python (EACL2021) In this blog post, I discuss our latest published paper on topic modeling: fbvinid.medium.com Colab of the Week ?
This is according to Barclay Hedge founder and President Sol Waksman in his July 2018 statement. That said; some of the commonly used historical data analysis methods used by hedge funds include the use of: Custom software such as Python and R; Robust trading platforms, such as MetaTrader 5 for hedge funds ; Efficient back-testing software.
This data will be analyzed using Netezza SQL and Python code to determine if the flight delays for the first half of 2022 have increased over flight delays compared to earlier periods of time within the current data (January 2019 – December 2021). Figure 7 – Initial query using the historical data (2003 – 2018).
There are around 3,000 and 4,000 plays from four NFL seasons (2018–2021) for punt and kickoff plays, respectively. GluonTS is a Python package for probabilistic time series modeling, but the SBP distribution is not specific to time series, and we were able to repurpose it for regression.
In 2018–2019, while new car sales were recorded at 3.6 These are common Python libraries used for data analysis and visualization. Submission Suggestions Linear Regression for tech start-up company Cars4U in Python was originally published in MLearning.ai million units, around 4 million second-hand cars were bought and sold.
Lambda natively supports Java, Go, PowerShell, Node.js, C#, Python, and Ruby code. Prompt the agent to build an optimal portfolio using the collected data What are the closing prices of stocks AAAA, WWW, DDD in year 2018? This optimized portfolio allocation maximizes returns while minimizing risk based on the 2018 stock prices.
If you are good with Python, AI, ML, APIs, py-cord, or setting up a machine/server, connect with him in the Discord thread! Introduced in 2018, BERT has been a topic of interest for many, with many articles and YouTube videos attempting to break it down. Keep an eye on this section, too — we share cool opportunities every week!
describe() count 9994 mean 2017-04-30 05:17:08.056834048 min 2015-01-03 00:00:00 25% 2016-05-23 00:00:00 50% 2017-06-26 00:00:00 75% 2018-05-14 00:00:00 max 2018-12-30 00:00:00 Name: Order Date, dtype: object Average sales per year df['year'] = df['Order Date'].apply(lambda Yearly average sales. Convert it into a graph.
From the purple line, we can see that our dataset has a non-stationary positive trend, where the monthly average price dropped in mid-2018 and stabilized at the beginning of 2019, but then the average price started to spike in mid-2020. On the other hand, the purple line shows the trend of the data.
A LinkedIn Workforce Report in 2018 found 151,000 unfilled data scientist jobs across the United States, with “acute” shortages in San Francisco, Los Angeles, and New York City. Click to learn more about author Itamar Ben Hamo. Data scientists are some of the most in-demand professionals on the market.
Solution overview In this blog, we will walk through the following scenarios : Deploy Llama 2 on AWS Inferentia instances in both the Amazon SageMaker Studio UI, with a one-click deployment experience, and the SageMaker Python SDK. Fine-tune Llama 2 on Trainium instances in both the SageMaker Studio UI and the SageMaker Python SDK.
Right now, most deep learning frameworks are built for Python, but this neglects the large number of Java developers and developers who have existing Java code bases they want to integrate the increasingly powerful capabilities of deep learning into. Business requirements We are the US squad of the Sportradar AI department. With v0.21.0
When my Python script started creating images the explorer.exe process would notice and immediately start trying to lay out icons. Instead you can read about how I used 19 different commute methods in September 2018 , or 20 different commute methods in April 2017. See for example this , this , this , this , this , and many more.
The following figure shows RGB channels of consecutive satellite visits representing the vegetative and reproductive stages of the corn phenology cycle, with (right) and without (left) crop masks (CW 20, 26 and 33, 2018 Central Illinois). Clean up If you no longer want to use this solution, you can delete the resources it created.
Prerequisites For this tutorial, you need a bash terminal with Python 3.9 Deploy fake news detection using the Amazon Bedrock API The solution uses the Amazon Bedrock API, which can be accessed using the AWS Command Line Interface (AWS CLI), the AWS SDK for Python (Boto3) , or an Amazon SageMaker notebook.
Python, Data Mining, Analytics and ML are one of the most preferred skills for a Data Scientist. For example, if you are a Data Scientist, then you should add keywords like Python, SQL, Machine Learning, Big Data and others. Expansive Hiring The IT and service sector is actively hiring Data Scientists. Wrapping it up !!!
Actually, you can develop such a system using state-of-the-art language models and a few lines of Python. In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. Each question should have 4 options.
MAPs can use both predefined and customized operators for DICOM image loading, series selection, model inference, and postprocessing We have developed a Python module using the AWS HealthImaging Python SDK Boto3. We have used a prebuilt container with Python 3.8 To create a SageMaker model, you will need to load a model.tar.gz
we present a series of UD benchmarks comparable to the Stanza and Trankit evaluations on Universal Dependencies v2.5 , using the evaluation from the CoNLL 2018 Shared Task. python -m pip install [link] Be aware that this will additionally install spacy-experimental to provide the experimental tokenizer and lemmatizer.
Introduction of Large Language Models One of the most influential LLMs is the GPT (Generative Pre-trained Transformer) model, which was first introduced by OpenAI in 2018. Programming Skills : LLMs are typically developed using programming languages like Python, so it’s essential to have strong programming skills.
Instead of building a model from… github.com NERtwork Awesome new shell/python script that graphs a network of co-occurring entities from plain text! Instead of building a model from… github.com Speech/Audio balavenkatesh3322/audio-pretrained-model A pre-trained model is a model created by some one else to solve a similar problem.
In our example, we will use LiDAR point cloud data to analyze changes in the landscape after category 5 Hurricane Michael blew through the Florida Panhandle in 2018. Snowflake’s capabilities in processing massive point cloud data sources are further enhanced by its specialized geospatial functions and Snowpark for Python scripting.
For example, to use the RedPajama dataset, use the following command: wget [link] python nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py From 2015–2018, he worked as a program director at the US NSF in charge of its big data program. He founded StylingAI Inc., Before joining the industry, he was the Charles E.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























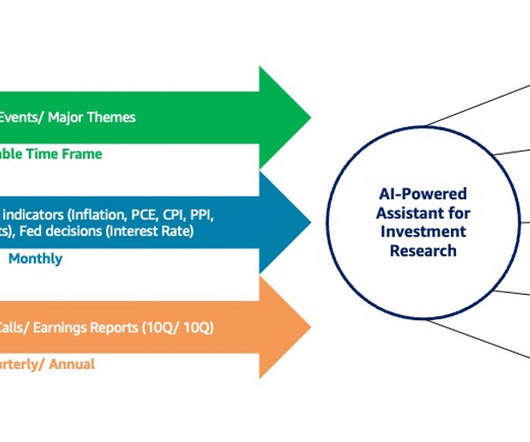













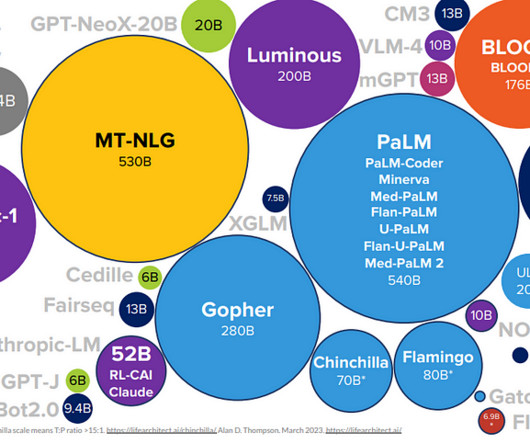









Let's personalize your content