This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An additional 2018 study found that each SLR takes nearly 1,200 total hours per project. This includes one paper from 2020 that conducted feature extraction using a denoising autoencoder alongside a deep neural network, and a flattened vector and supportvectormachines to evaluate study relevance. dollars apiece.
AI practitioners choose an appropriate machine learning model or algorithm that aligns with the problem at hand. Common choices include neural networks (used in deep learning), decision trees, supportvectormachines, and more. With the model selected, the initialization of parameters takes place.
The earlier models that were SOTA for NLP mainly fell under the traditional machine learning algorithms. These included the Supportvectormachine (SVM) based models. 2018) “ Language models are few-shot learners ” by Brown et al. 2020) “GPT-4 Technical report ” by Open AI.
In 2018, there were extensive news reports that an Uber self-driving car made an accident with a pedestrian in Tempe, Arizona. The pedestrian died, and investigators found that there was an issue with the machine learning (ML) model in the car, so it failed to identify the pedestrian beforehand.
Moreover, random forest models as well as supportvectormachines (SVMs) are also frequently applied. In this formula, is the cardinality of a specific coalition and the sum extends over all subsets of that do not contain the marginal contribution of channel to the coalition. References Zhao, K., Mahboobi, S.
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: SupportVectorMachine , S upport Vectors and Linearly vs. Non-linearly Separable Data. The linear kernel is ideal for linear problems, such as logistic regression or supportvectormachines ( SVMs ).
The following code snippet demonstrates how to aggregate raster data to administrative vector boundaries: import geopandas as gp import numpy as np import pandas as pd import rasterio from rasterstats import zonal_stats import pandas as pd def get_proportions(inRaster, inVector, classDict, idCols, year): # Reading In Vector File if '.parquet'
In 2018, over 1000 papers have been released on ArXiv per month in the above areas. Instead, we manually defined the important set of concepts from the larger set of most common n-grams — “recurrent neural networks”, “supportvectormachine”, etc. Every month except January. Over 2000 papers were released in November.
Sentence embeddings can also be used in text classification by representing entire sentences as high-dimensional vectors and then feeding them into a classifier. SentenceBERT: Currently, the leader among the pack, SentenceBERT was introduced in 2018 and immediately took the pole position for Sentence Embeddings.
For more information, including a worked example of how to compute mAP, please see Hui (2018). Step #4: Classify each proposal using the extracted features with a SupportVectorMachine (SVM). The (Faster) R-CNN Architecture In this section, we’ll review the Faster R-CNN architecture.
Health startups and tech companies aiming to integrate AI technologies account for a large proportion of AI-specific investments, accounting for up to $2 billion in 2018 ( Figure 1 ). These investments range from digital diagnosis to clinician decision support to precision medicine. Diabetic Retinopathy, see Figure 9 ).
profanity-filter profanity-filter uses Machine Learning! Transform : turns each text string in the dataset into its vector form. Training: Linear SVM The model I decided to use was a Linear SupportVectorMachine (SVM), which is implemented by scikit-learn ’s LinearSVC class. F **g Blue Shells.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









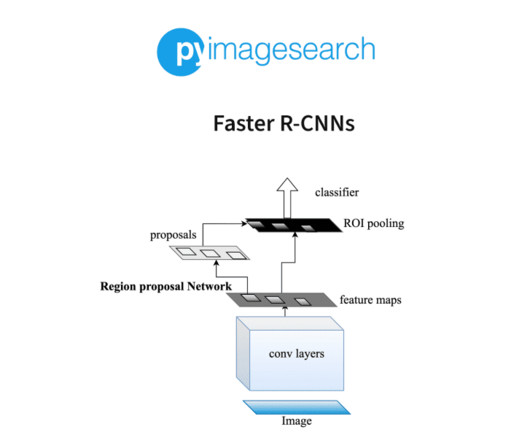








Let's personalize your content