This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Increase your confidence to perform datacleaning with a broader perspective of what datasets typically look like, and follow this toolbox of code snipets to make your datacleaning process faster and more efficient.
As a data scientist, you can get lost in your daily dives into the data. Consider this advice to be certain to follow in your work for being diligent and more impactful for your organization.
Careful preprocessing of data for your machine learning project is crucial. This overview describes the process of datacleaning and dealing with noise and missing data.
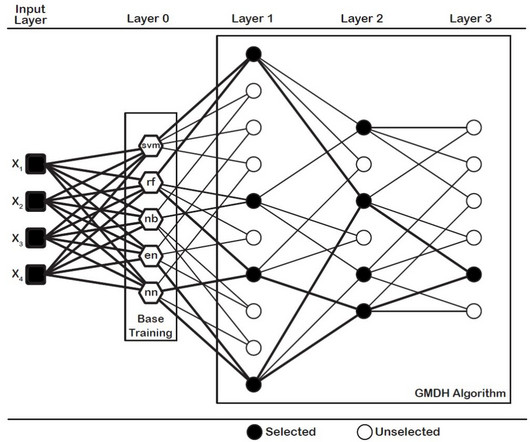
Binary Classification via dce-GMDH Algorithm in R Subscribe to YouTube Channel Don’t forget to check: 6 Ways of Subsetting Data in R References Dag, O., For reproducibility of results, let’s fix the seed number to 1234. dce-GMDH algorithm is available in GMDH2 package (Dag et al., Karabulut, E.,
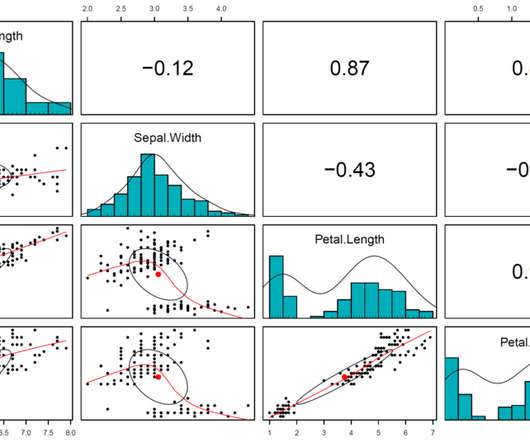
Dr. Osman Dag LinkedIn Twitter Mail The post 16 Different Methods for Correlation Analysis in R appeared first on Universe of Data Science. Find out how to apply correlation analysis in R. In this guide, we will work on 16 different correlation coefficients in R. These coefficients are listed below. For this purpose, we use rename argument.
Models were trained and cross-validated on the 2018, 2019, and 2020 seasons and tested on the 2021 season. He has been with the Next Gen Stats team for the last seven years helping to build out the platform from streaming the raw data, building out microservices to process the data, to building API’s that exposes the processed data.
It can be gradually “enriched” so the typical hierarchy of data is thus: Raw data ↓ Cleaneddata ↓ Analysis-ready data ↓ Decision-ready data ↓ Decisions. For example, vector maps of roads of an area coming from different sources is the raw data. Data, 4(3), 92. Data, 4(3), 94.
While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it. According to a 2019 survey by Deloitte , only 18% of businesses reported being able to take advantage of unstructured data. Cleandata is important for good model performance.
And those who practice these “old school” governance methods have little confidence in their efficacy: 73% of Ventana research participants stated that spreadsheets were a data governance concern for their organization, while 59% viewed incompatible tools as the top barrier to a single source of truth. And it’s growing in popularity.
During training, the input data is intentionally corrupted by adding noise, while the target remains the original, uncorrupted data. The autoencoder learns to reconstruct the cleandata from the noisy input, making it useful for image denoising and data preprocessing tasks.
Ryan Cairnes Senior Manager, Product Management, Tableau Hannah Kuffner July 28, 2020 - 10:43pm March 20, 2023 Tableau Prep is a citizen data preparation tool that brings analytics to anyone, anywhere. With Prep, users can easily and quickly combine, shape, and cleandata for analysis with just a few clicks. billion records!
Ryan Cairnes Senior Manager, Product Management, Tableau Hannah Kuffner July 28, 2020 - 10:43pm March 20, 2023 Tableau Prep is a citizen data preparation tool that brings analytics to anyone, anywhere. With Prep, users can easily and quickly combine, shape, and cleandata for analysis with just a few clicks. billion records!
Advances in neural information processing systems 32 (2019). Visualizing data using t-SNE.” He has been with the Next Gen Stats team for the last seven years helping to build out the platform from streaming the raw data, building out microservices to process the data, to building API’s that exposes the processed data.
Finding the Best CEFR Dictionary This is one of the toughest parts of creating my own machine learning program because cleandata is one of the most important parts. I let only the word with the pos of NOUN, VERB, ADJ, and ADV to pass through the filter and continue to the next process. The approach was proposed by Yin et al.
Customers must acquire large amounts of data and prepare it. This typically involves a lot of manual work cleaningdata, removing duplicates, enriching and transforming it. It’s also not easy to run these models cost-effectively.
At first it was due to a lack of cleandata, which was easily remedied thanks to DVC and DagsHub, allowing us to quickly swap out our dataset with a quality rated version, which had significantly better outputs, some of these results from early models can be found below.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content