This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For our final structured and unstructured datapipeline, we observe Anthropic’s Claude 2 on Amazon Bedrock generated better overall results for our final datapipeline. This occurred in 2019 during the first round on hole number 15. We selected Anthropic’s Claude v2 and Claude Instant on Amazon Bedrock.
It does not support the ‘dvc repro’ command to reproduce its datapipeline. DVC Released in 2017, Data Version Control ( DVC for short) is an open-source tool created by iterative. Adding new data to the storage requires pulling the existing data, then calculating the new hash before pushing back the whole data.
Such growth makes it difficult for many enterprises to leverage big data; they end up spending valuable time and resources just trying to manage data and less time analyzing it. One way to address this is to implement a data lake: a large and complex database of diverse datasets all stored in their original format.
Having gone public in 2020 with the largest tech IPO in history, Snowflake continues to grow rapidly as organizations move to the cloud for their data warehousing needs. The December 2019 release of Power BI Desktop introduced a native Snowflake connector that supported SSO and did not require driver installation.
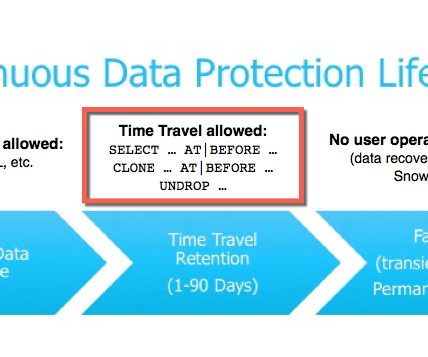
Access Controls and User Authentication Access control regulates who can interact with various database objects, such as tables, views, and functions. In Snowflake, securable objects (representing database resources) are controlled through roles. HITRUST: Meeting stringent standards for safeguarding healthcare data.
Utilizing Streamlit as a Front-End At this point, we have all of our data processing, model training, inference, and model evaluation steps set up with Snowpark. Streamlit, an open-source Python package for building web-apps, has grown in popularity since its launch in 2019. Let’s continue by creating a front-end to enable analysts.
However, in scenarios where dataset versioning solutions are leveraged, there can still be various challenges experienced by ML/AI/Data teams. Data aggregation: Data sources could increase as more data points are required to train ML models. Existing datapipelines will have to be modified to accommodate new data sources.
The Inferentia chip became generally available (GA) in December 2019, followed by Trainium GA in October 2022, and Inferentia2 GA in April 2023. An important part of the datapipeline is the production of features, both online and offline. All the way through this pipeline, activities could be accelerated using PBAs.
He previously co-founded and built Data Works into a 50+ person well-respected software services company. In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, data engineering and data analytics.
Fastweb , one of Italys leading telecommunications operators, recognized the immense potential of AI technologies early on and began investing in this area in 2019. With a vision to build a large language model (LLM) trained on Italian data, Fastweb embarked on a journey to make this powerful AI capability available to third parties.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content