This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
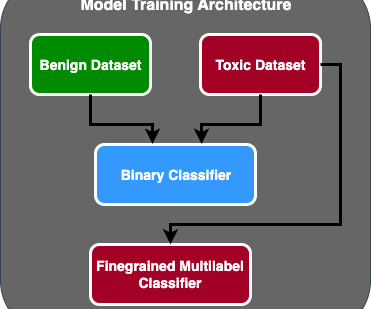
This article was published as a part of the DataScience Blogathon. Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervisedlearning of language representations, which shares the same architectural backbone as BERT. The key […].
Given the availability of diverse data sources at this juncture, employing the CNN-QR algorithm facilitated the integration of various features, operating within a supervisedlearning framework. Utilizing Forecast proved effective due to the simplicity of providing the requisite data and specifying the forecast duration.
In this post, we detail our collaboration in creating two proof of concept (PoC) exercises around multi-modal machine learning for survival analysis and cancer sub-typing, using genomic (gene expression, mutation and copy number variant data) and imaging (histopathology slides) data.
AWS received about 100 samples of labeled data from the customer, which is a lot less than the 1,000 samples recommended for fine-tuning an LLM in the datascience community. The bertweet-base-hate model also uses the base BertTweet FM but is further pre-trained on 19,600 tweets that were deemed as hate speech 8 (Basile 2019).
2019) DataScience with Python. 2019) Applied SupervisedLearning with Python. Skicit-Learn (2023): Cross-validation: evaluating estimator performance, available at: [link] [5 September 2023] WRITER at MLearning.ai / AI Agents LLM / Good-Bad AI Art / Sensory Mlearning.ai Reference: Chopra, R.,
There are various types of regressions used in datascience and machine learning. In social science, we can predict the ideology of individuals based on their age. Conclusion This article described regression which is a supervisinglearning approach. 2019) DataScience with Python.
2019) DataScience with Python. 2019) Applied SupervisedLearning with Python. 2019) Python Machine Learning. References: Chopra, R., England, A. and Alaudeen, M. Packt Publishing. Available at: [link] (Accessed: 25 March 2023). Johnston, B. and Mathur, I. Packt Publishing. Raschka, S.
While rarely an endpoint, large language model (LLM) distillation lets datascience teams kickstart the data development process and get to a production-ready model faster than they could with traditional approaches. Due to the quantity of calculations necessary, full-sized LLMs can be slow. Infrastructure headaches.
While rarely an endpoint, large language model (LLM) distillation lets datascience teams kickstart the data development process and get to a production-ready model faster than they could with traditional approaches. Due to the quantity of calculations necessary, full-sized LLMs can be slow. Infrastructure headaches.
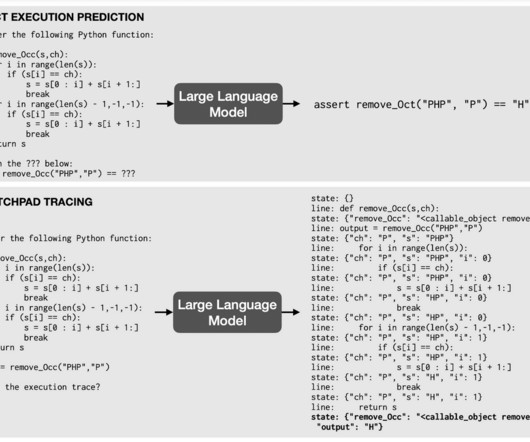
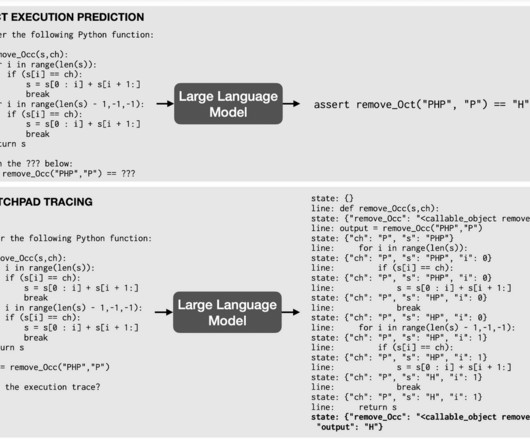
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” OpenAI’s GPT-2, finalized in 2019 at 1.5
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” OpenAI’s GPT-2, finalized in 2019 at 1.5
Most solvers were datascience professionals, professors, and students, but there were also many data analysts, project managers, and people working in public health and healthcare. To increase the amount of data, I tried to generate data using some LLMs in a few-shot way. Alejandro A.
[link] David Mezzetti is the founder of NeuML, a data analytics and machine learning company that develops innovative products backed by machine learning. He previously co-founded and built Data Works into a 50+ person well-respected software services company. What supervisedlearning methods did you use?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content