This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction What kind of database did you use to build your most recent application? According to Scalegrid’s 2019database trends report, SQL is the most popular database form, with more than 60% of its use. It is followed by NoSQL databases with more than 39% use.
In this blog, let us explore data science and its relationship with SQL. As long as there is ‘data’ in data scientist, Structured Query Language (or see-quel as we call it) will remain an important part of it.
Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and Azure Data Lake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. Azure Synapse. I think this announcement will have a very large and immediate impact. R Support for Azure Machine Learning.
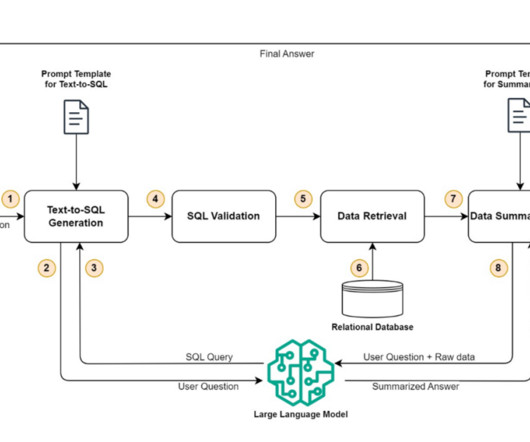
From a broad perspective, the complete solution can be divided into four distinct steps: text-to-SQL generation, SQL validation, data retrieval, and data summarization. A pre-configured prompt template is used to call the LLM and generate a valid SQL query. The following diagram illustrates this workflow.
The database for Process Mining is also establishing itself as an important hub for Data Science and AI applications, as process traces are very granular and informative about what is really going on in the business processes. This aspect can be applied well to Process Mining, hand in hand with BI and AI.
The Salesforce purchase in 2019. Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first EOM contract with the database company Hyperion—that’s when I was hired.
Someone with the knowledge of SQL and access to a Db2 instance, where the in-database ML feature is enabled, can easily learn to build and use a machine learning model in the database. In this post, I will show how to develop, deploy, and use a decision tree model in a Db2 database.
We formulated a text-to-SQL approach where by a user’s natural language query is converted to a SQL statement using an LLM. The SQL is run by Amazon Athena to return the relevant data. Our final solution is a combination of these text-to-SQL and text-RAG approaches. The following table contains some example responses.
Let’s check out the goodies brought by NeurIPS 2019 and co-located events! Balažević et al (creators of TuckER model from EMNLP 2019 ) apply hyperbolic geometry to knowledge graph embeddings in their Multi-Relational Poincaré model ( MuRP ). Graphs were well represented at the conference. Thank you for reading!
Netezza Performance Server (NPS) has recently added the ability to access Parquet files by defining a Parquet file as an external table in the database. All SQL and Python code is executed against the NPS database using Jupyter notebooks, which capture query output and graphing of results during the analysis phase of the demonstration.
Enter Power BI Report Builder, a tool that was released by Microsoft in 2019 that enables users to design and create paginated reports and then share them via Power BI service. The data sources with a “*” indicate that they require a Power BI gateway in order to access and share reports on the Power BI service.
DVC lacks crucial relational database features, making it an unsuitable choice for those familiar with relational databases. Dolt Created in 2019, Dolt is an open-source tool for managing SQLdatabases that uses version control similar to Git. Most developers are familiar with Git for source code versioning.
The Salesforce purchase in 2019. Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first OEM contract with the database company Hyperion—that’s when I was hired.
2019 - Delta Lake Databricks released Delta Lake as an open-source project. With the introduction of SQL capabilities, they are accessible to users who are accustomed to querying relational databases What is an External Table? It can also be integrated into major data platforms like Snowflake.
The most vital aspect of automating power bi DevOps is to understand the main pillars in the SQL DevOps cycle. In 2019, expect a seismic shift from CI pipelines to DevOps assembly lines. They can also spin up a new instance, automatically restore the database from a backup, or provision other recovery options.
According to a 2019 survey by Deloitte , only 18% of businesses reported being able to take advantage of unstructured data. Access to Amazon OpenSearch as a vector database. The choice of vector database is an important architectural decision. In this example, we have chosen Amazon OpenSearch as our vector database.
Figure 1: Magic Quadrant Cloud Database Systems Source: Gartner (December 2021) Power BI is a data visualization and analysis tool that is one of the four tools within Microsoft’s Power Platform. The December 2019 release of Power BI Desktop introduced a native Snowflake connector that supported SSO and did not require driver installation.
These tips can be used in any of your Prep flows but will have the most impact on your flows that connect to large database tables. This database table—dating back to 2019—contains a whopping 14.5 In this example, the SQL query took over 38 minutes to complete in the native database portal. billion records!
These tips can be used in any of your Prep flows but will have the most impact on your flows that connect to large database tables. This database table—dating back to 2019—contains a whopping 14.5 In this example, the SQL query took over 38 minutes to complete in the native database portal. billion records!
For instance, just like rating, reviewing and sharing a tourist spot on TripAdvisor you can start a conversation on a data object like a table, column, BI report or even a SQL query within Alation; endorse, warn or deprecate it as well as share it with another user or group. Get the 2019 Dresner Data Catalog Study.
To give a sense for the change in scale, the largest pre-trained model in 2019 was 330M parameters. Today, we’re excited to announce the general availability of Amazon CodeWhisperer for Python, Java, JavaScript, TypeScript, and C#—plus ten new languages, including Go, Kotlin, Rust, PHP, and SQL.
Streamlit, an open-source Python package for building web-apps, has grown in popularity since its launch in 2019. Snowflake Dynamic Tables are a new(ish) table type that enables building and managing data pipelines with simple SQL statements. What was once a SQL-based data warehousing tool is now so much more.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor data quality and availability. One way to address this is to implement a data lake: a large and complex database of diverse datasets all stored in their original format.
Stefan: Back in 2019. My team had per view in terms of build versus buy, we’d been looking at like across the stack, and like we were seeing we created Hamilton back in 2019, and we were seeing very similar-ish things come out and be open-source – we’re like, “hey, I think we have a unique angle.” Stefan: Yeah.
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets. The LLM response is passed back to the agent.
For example, GPT-3 was trained on a web crawl dataset that included data collected up to 2019. A memory could be a structured database, a store for natural language, or a vector index that stores embeddings. These chunks are stored in a vector database, which indexes data with embeddings. What about the tools in LLM agents?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content