This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It is an annual tradition for Xavier Amatriain to write a year-end retrospective of advances in AI/ML, and this year is no different. Gain an understanding of the important developments of the past year, as well as insights into what expect in 2020.
Semi-Supervised Sequence Learning As we all know, supervisedlearning has a drawback, as it requires a huge labeled dataset to train. Generating Wikipedia By Summarizing Long Sequences This work was published by Peter J Liu at Google in 2019. But, the question is, how did all these concepts come together?
“Transformers made self-supervisedlearning possible, and AI jumped to warp speed,” said NVIDIA founder and CEO Jensen Huang in his keynote address this week at GTC. Transformers are in many cases replacing convolutional and recurrent neural networks (CNNs and RNNs), the most popular types of deeplearning models just five years ago.
Using such data to train a model is called “supervisedlearning” On the other hand, pretraining requires no such human-labeled data. This process is called “self-supervisedlearning”, and is identical to supervisedlearning except for the fact that humans don’t have to create the labels.
It’s better than the top-word (zero temperature) case, but still at best a bit weird: This was done with the simplest GPT-2 model (from 2019). And many of the practical challenges around neural nets—and machine learning in general—center on acquiring or preparing the necessary training data. Here’s a random example.
I love participating in various competitions involving deeplearning, especially tasks involving natural language processing or LLMs. I generated unlabeled data for semi-supervisedlearning with Deberta-v3, then the Deberta-v3-large model was used to predict soft labels for the unlabeled data. Alejandro A.
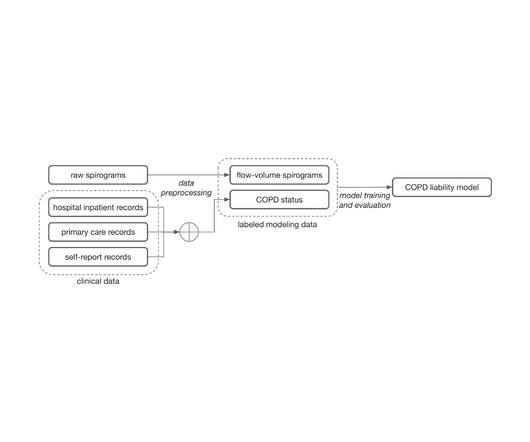
In “ Inference of chronic obstructive pulmonary disease with deeplearning on raw spirograms identifies new genetic loci and improves risk models ”, published in Nature Genetics , we’re excited to highlight a method for training accurate ML models for genetic discovery of diseases, even when using noisy and unreliable labels.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









Let's personalize your content